Object Event Modeling and Simulation
Discrete Event Simulation Engineering
Copyright © 2023-24 Gerd Wagner
Draft version, published 2024-08-18.

Abstract
This book explains how to make models for Discrete Systems (including Information Systems) engineering and for Discrete Event Simulation engineering using the Unified Modeling Language (UML) and the Discrete Event Process Modeling Notation (DPMN) and following the paradigm of Object Event Modeling and Simulation (OEM&S), which combines the Software Engineering paradigm of Object-Oriented Modeling with the Discrete Event Simulation paradigm of Event-Based Simulation (also called Event Scheduling).
The modeling concepts of OEM&S, in particular the concepts of objects, events and activities, are ontologically grounded on corresponding categories of the Unified Foundational Ontology (UFO).
This monography provides the foundations of the textbooks Discrete Event Simulation Engineering and Business Process Modeling and Simulation with DPMN, which have overlapping contents.
Table of Contents
- List of Figures
- List of Tables
- I. Object Event Modeling
- II. Event-Based Simulation
- III. Activity-Based Simulation and Activity Networks
- 6. Design Modeling of Simple Activities
- 7. Resource-Constrained Activities
- IV. Processing Activities and Processing Networks
- V. Formal Semantics of OEM
- VI. Agent-Based Modeling and Simulation
- Bibliography
- Index
List of Figures
- 2-1. Introducing an activity type in a conceptual information model of a single workstation system.
- 2-2. Introducing an activity type in a conceptual process model of a single workstation system.
- 3-1. An OE class diagram providing an information design for the Public Library IS.
- 3-2. A business process design model describing a flexible business process type.
- 3-3. A business process design model describing a workflow process type.
- 5-1. A basic DPMN Process Diagram showing an OEG.
- 5-2. A basic OE class model defining an object type and three event types.
- An example of a simple AN
- 6-1. Going from basic OEM to OE class models by introducing activity types.
- 6-2. Going from basic DPMN to DPMN-AN process models by introducing Activity rectangles.
- 6-3. Allocating the workstation as a resource of Processing activities
- 7-1. Typically, the performer of an activity is a resource object.
- 7-2. Activity types may have special properties representing resource roles.
- 7-3. A conceptual information model of the activity type "examinations" with resource roles.
- 7-4. A conceptual process model based on the information model of Figure 7-3.
- 7-5. A conceptual information model with doctors and patients as people.
- 7-6. Adding the activity type "walks to room" to the conceptual information model.
- 7-7. A conceptual process model based on the information model of Figure 7-6.
- 7-8. An improved process model based on the information model of Figure 7-6.
- 7-9. Displaying the process owner and activity performers in a conceptual process model.
- 7-10. Adding multitasking multiplicities for rooms participating both in walks and examinations, possibly at the same time.
- 7-11. An information model for the simplified design with the resource counters nmrOfRooms and nmrOfDoctors.
- 7-12. A process design model based on the information design model of Figure 7-11.
- 7-13. An OE class model with resource object types for modeling resource roles and pools.
- 7-14. A process design model based on the information design model of Figure 7-13.
- 7-15. Any resource type R extends the pre-defined object type
Resource - 7-16. A simplified version of the model of Figure 7-13
- 7-17. An OE Class Diagram modeling a single workstation system with resource-constrained processing activities
- 7-18. An information design model for decoupling the allocation of rooms and doctors.
- 7-19. A process design model based on the information design model of Figure 7-18.
- 7-20. Representing the process owner as a Pool and activity performers as Lanes in a process design model.
- 7-21. A conceptual modeling pattern for a sequence of resource-constrained activities
- 7-22. Using RDAS arrows in a conceptual process model.
- 7-23. Displaying the implicit allocate-release steps.
- 7-24. Modeling WorkStation as a resource type
- 7-25. A simplified version of the workstation process model using an RDAS arrow.
- 7-26. A simplified version of the medical department information model with Doctor and Room as resource types
- 7-27. A simplified version of the medical department process model using RDAS arrows.
- 7-28. Doctors perform examinations.
- 7-29. An examination requires two resources: a room and a doctor.
- 7-30. The class Examination implementing the corresponding activity type.
- 7-31. The loading of a truck requires at least one, and can be handled by at most two, wheel loaders.
- 7-32. The class LoadTruck implementing the corresponding activity type.
- 7-33. An examination room may be used by up to 3 examinations at the same time.
- 7-34. The teaching of a course is performed by teachers.
- Resource-constrained activities involving processing objects are processing activities.
- 8-1. A conceptual OEM class model defining built-in types for conceptual PN modeling
- 8-2. A PN model using the new DPMN modeling elements of PN Node rectangles, Processing Flow arrows and Object-Event Flow arrows
- 8-3. A DPMN-PN process diagram with an Event Scheduling arrow
- 9-1. An OEM class design model defining built-in types for making PN design models
- 9-2. A PN model of a workstation system using PN Node rectangles and PN Flow arrows
- 9-3. A PN model of a workstation system where parts may have to be reworked
- 9-4. A PN model using the new DPMN modeling elements of PN Node rectangles and PN Flow arrows
- The abstract syntax of the OE Modeling Language based on KerML meta-classes.
List of Tables
Part I. Object Event Modeling
Chapter 1. Introduction
The world consists of objects and events. “Smiles, walks, dances, weddings, explosions, hiccups, hand-waves, arrivals and departures, births and deaths, thunder and lightning: the variety of the world seems to lie not only in the assortment of its ordinary citizens—animals and physical objects, and perhaps minds, sets, abstract particulars—but also in the sort of things that happen to or are performed by them” (Casati and Varzi 2015).
While research in Business Process Modeling has focused on events and processes, neglecting objects, research in Conceptual Modeling for Information Systems engineering has focused on objects, neglecting events. Object Event Modeling (OEM) reconciles both perspectives, giving equal weight to objects and events as two kinds of entities.
OEM is a new paradigm for modeling discrete dynamical systems, including organizations and their process-supportive information systems. OEM combines information modeling with discrete process modeling.
An Object Event (OE) model is a triple ⟨OT, ET, R⟩, consisting of
- a set of object types OT,
- a set of event types ET, and
- a set of event rules R, which capture causal regularities.
Both object types and event types are defined with attributes, operations and constraints, like classes in UML class models. Attributes are defined with a name and a range (also called codomain), which is either a datatype or another entity type. Special attributes, also called reference attributes, represent associations, hence their range is an entity type.
While object types and event types can be defined in an information model, e.g., visually as a UML Class Diagram or textually in the form of class definitions, event rules can be defined visually in a discrete process model diagram, such as an Object Event Graph or an Activity Network, or textually in the form of rule statements. Thus, an OE model is provided by a combination of an information model with a discrete process model.
The formal semantics of an OE model ⟨OT, ET, R⟩ is defined in (Wagner 2017) in the form of an Abstract State Machine, which is an expressive kind of state transition system, whose state structure is defined by the object and event types of OT and ET, and whose transition functions are provided by the event rules of R. Since an OE model is executable, it is a special type of a Discrete Event Simulation (DES) model.In OEM, an information model defines the types of objects, events and activities of a problem domain, with their attributes, associations, operations and constraints, typically in the form of an OE Class Model, which is a UML Class Model with the class categories «object type», «event type» and «activity type». In OEM, an activity is a special kind of non-instantaneous event that is composed of an instantaneous activity start event followed by an instantaneous activity end event.
OEM has originally been developed as an approach for DES modeling (Wagner 2018), and only later, in (Wagner 2022), for Information System (IS) modeling. Essentially, the same types of entities, and their associations, as well as the same types of processes, have to be modeled both for making a DES model of, and for making a process-supportive IS model for, an organization.
Since DES engineering projects and IS engineering projects have different goals, they need different (but nevertheless overlapping) models. However, one important case is the simulation of an IS in the broader sense, including the interactions between the IS and its users, which can also be viewed as the simulation of an organization as a discrete dynamical system including the organization's IS as a subsystem. In this case, the DES model is an extension of the IS model and the steps needed for turning an IS model into a DES model are sketched in Section 1.2
1.1. Ontological Foundations of OEM
OEM’s concepts of objects (and object types) as well as events (and event types), and the concept of participation associations between object types and event types, are ontologically grounded on the Unified Foundational Ontology (UFO), specifically on its ontology of endurants/objects (UFO-A) and its ontology of perdurants/events (UFO-B) (Guizzardi et al 2022). However, there are several open issues concerning the OEM concepts of (discrete and continuous) processes, activities, causal regularities and dynamical systems.
OntoUML is a conceptual modeling language based on UML Class Diagrams and UFO. OEM has been developed independently of, and prior to, the extended version of OntoUML that covers event modeling (Almeida, Falbo and Guizzardi. 2019). There are the following mismatches:
- In OEM, creation and termination of objects have not (yet) been considered and a commitment to a “historical semantics” not only for event types, but also for object types, has been avoided. For practical modeling purposes it is preferable not to impose a “historical semantics” on all object types, which would require to keep terminated objects in the universe of discourse (and in the extension of corresponding database tables), but only impose such a semantics on event types requiring to keep historical events in the universe of discourse (and corresponding event records in the underlying database).
- While OntoUML only considers history multiplicities at the event type association ends of participation associations, OEM allows both for snapshot multiplicities and for history multiplicities (see Section 2.1.4).
Processes
UFO-B does not (yet) cover the ontological foundations of processes as a particular category of perdurants. Only recently, Guarino and Guizzardi (2024) have been proposing a new ontological theory of processes essentially stating that
- For allowing the same process to be ongoing (while “accumulating events”) and later completed, processes should be considered as “variable embodiments” in the sense of (Fine 2022).
- The completion of a process creates a corresponding (process-as-)event with the same start and end time.
- There are a number of conceptual distinctions among basic process kinds: (1) structurally homogeneous processes, (2) intentional processes, and (3) telic processes. E.g., business processes are complex telic processes.
However, Guarino and Guizzardi do not consider the distinction between discrete processes and continuous processes (such as the rotation of the earth around the sun). Unlike the former, the latter are not “accumulating events”.
Activities
Activities are special processes: they may be both ongoing and completed. While completed activities may be loosely identified with the corresponding (activity-as-)event, this does not apply to ongoing activities.
In (Fine 2022), activities are defined as “processes whose manifestations are sequences of intentional acts of the same kind, and are described by verbal expressions such as walking, running, eating apples, etc.” However, this concept of activities as quasi-homogeneous processes deviates from the ordinary language use of the term, e.g., in the area of Business Process Management, where any subprocess performed by the same actor(s) can be considered to be an activity.
Causal Regularities
In UFO-B, causation has only be considered at the level of individuals (in the form of events causing other events), but not as a pattern, or causal regularity, at the level of types.
In OEM, event rules express causal regularities where events of a certain type cause state changes of affected objects and follow-up events.
Dynamical Systems
The concept of dynamical systems is widely used in mathematics and the natural sciences, but also in certain social sciences such as economics. In some works, the term “discrete dynamical system” is mistakenly defined as a dynamical system for which time is discrete.
The general concept rather refers to the nature of the state changes of a system. If a system has only continuous state changes, it is a continuous dynamical system, while if it has only discrete state changes, it is a discrete dynamical system.
UFO does not (yet) have a theory of dynamical systems.
1.2. Turning an IS Model into a DES Model
The steps needed for turning an IS model into a DES model can be sketched as follows:
- For each activity type A, (a) for each attribute Attr of A, add a function getAttr that returns a random value for Attr; (b) add an activity duration function, which either returns a constant value representing the average duration of activities of this type or a value sampled from a probability distribution modeling the random variation of the duration of activities of this type. In a simulation run, when an activity is started, the simulator computes (a) a random value for each attribute Attr by invoking getAttr, (b) its duration by invoking the activity duration function.
- Add a recurrence function to each start event type. This function may either return a constant value representing the average time in-between two consecutive start events of this type or a value sampled from a probability distribution modeling the random variation of this time. In a simulation run, the simulator computes the first and all successive occurrence times of start events of this type by invoking this function.
- For each organizational position, add a human resource pool consisting of a realistic number of resource objects representing staff required for performing activities.
- For each passive resource object type, add a resource pool consisting of a realistic number of corresponding resource objects.
1.3. Modeling Events in UML and SysML
The UML standardization effort has been concerned with Object-Oriented (OO) modeling, but it has missed the modeling of events and the opportunity of modeling behavior/processes based on a general concept of events and their state changes. Instead, UML contributors have been obsessed with the computational concept of state machines requiring to name all relevant states of an object, which is an approach that does not scale.
It is rather strange that even in the new Kernel Modeling Language, the behavior/process modeling concepts of Behaviors and Interactions are defined without even mentioning the term “event”.
Olivé and Raventós (2006) presume that in UML, events have not been considered as first-class citizens (as instances of event classes), but rather in the limited form of operation invocations, due to the desire to separate “structural modeling” from “behavioral modeling”.
The UML-based System Modeling Language (SysML) allows modeling “blocks” (representing system components), which can be connected via “ports” for allowing data flows and signal flows between “blocks”. This approach is good for modeling digital systems, where the "ports" of a "block" represent the pins of an electronics component, but it is not suitable for modeling other types of discrete dynamical systems such as discrete manufacturing systems or supply chain systems.
UML/SysML limit the concept of events to specific uses in State Machine Diagrams and Activity Diagrams (“Call Event”,”Change Event”,”Signal Event”,”Time Event”). Unlike OEM, UML/SysML do not support a general concept of events, which would include UI events and business events.
1.4. Related Work
Unlike in the field of DES, in the field of IS engineering the idea of modeling events as entities in information models and combining this with modeling objects is not new. Already Peter Chen (1976), in his seminal paper proposing Entity-Relationship (E-R) modeling, suggested that both objects and events should be modelled as entities: “A specific person, company, or event is an example of an entity”. Motivated by the importance of events such as sales, purchases, or cash receipts, in accounting, McCarthy (1979) has proposed to model these events, along with objects, as entities in E-R models. However, neither Chen nor McCarthy considered the fundamental semantic differences between these two kinds of entities and treated them in the same way.
Independently of each other, Allen and March (2003) as well as Olivé and Raventós (2006) have proposed modeling events as entities in information models taking into consideration how they affect the state of objects.
Allen and March (2003) propose to include the events responsible for object state changes as entities in an E-R model arguing that this approach is preferable to temporal database approaches whenever temporality is needed. March and Allen (2009), by stating that “an information system must be conceptualized as an event-processing mechanism and an event as the cause of the transition from an initial state to a subsequent state via the application of its rules”, already have been aware of the concept of event rules as transition functions, which is the basis of the semantics of DPMN process models (Wagner 2017).
Olivé and Raventós (2006) propose modelling events as entities and event types as classes with a special effect() operation in UML class models. Their effect() operation essentially corresponds to the OEM concept of event rules, or the event handlers onEvent() and onActivityEnd() in OEMjs. Olivé and Raventós integrate information and behavior/process modeling in their extended form of UML class diagrams. However, it seems preferable to separate behavior/process modeling from information modeling. While the latter is in charge of defining the types of objects, events and activities (including their attributes, associations, operations and constraints), the former is in charge of defining event rules, which define the effects of events and the admissible sequences of events.
Neither Allen and March nor Olivé and Raventós have made a distinction between instantaneous events and activities.
Chapter 2. Making Conceptual Domain Models
A conceptual domain model describes a problem domain (or real-world system under investigation) by describing its relevant types of objects and events in an information model (typically in the form of a class diagram), and by describing its causal regularities, or its dynamics, in a process model in the form of event rules, e.g., expressed in an Object Event Graph, helping to understand what's going on in the system.
2.1. Making Conceptual Information Models
A conceptual information model describes the subject matter vocabulary used, e.g., in the system narrative, in a semi-formal way. Such a vocabulary essentially consists of names for
- types, corresponding to classes in OO modeling, or unary predicates in formal logic,
- attributes, corresponding to binary predicates in formal logic,
- associations, corresponding to n-ary predicates (with n > 1) in formal logic.
The main categories of types are object types and event types. A simple form of conceptual information model is obtained by providing a list of each of them, while a more elaborated model, e.g., in the form of a UML class diagram, also defines attributes and associations, including those that describe the participation of objects (of certain types) in events (of certain types).
2.1.1. Modeling Object Types
Object types are modeled in OE class diagrams in the form of class rectangles categorized with the ("stereotype") keyword «object type».
As an illustrating example, consider a public library, which lends book copies to its users. For this organization, the most important object types are Book, BookCopy, Person, and LibraryUser, as described by the following class diagram:
This model includes two associations and one specialization:
- The functional (many-to-one) association between book copy and book associating exactly one book with any book copy, and, inversely, zero to many book copies with any book.
- The non-functional (many-to-many) association between book and person associating zero to many people as authors with a book, and, inversely, zero to many books with any person as one of their authors.
- The specialization from library user to person stating that any library user is also a person and, hence, also has the attributes id, name, birth date and biography.
Different Categories of Object Types
In order to better understand the different categories of object types and their subtypes in natural language statements about the real world and in information models, we can distinguish between sortal and non-sortal, and between rigid and non-rigid object types, as proposed by Giancarlo Guizzardi in his theory of object type categories, which is presented in Chapter 4 of (Guizzardi 2005).
An object type is sortal if it has a uniform identity condition for its instances. Such a condition defines the property (or set of properties) that no two instances can have in common, without being the same object. An example of a sortal object type is Person since all its instances (people) are identifiable by a set of properties related to their birth (born when, where and to whom).
Non-sortal types, such as Thing and Entity, are called dispersive. They can be partitioned into a set of sortal sub-types with different principles of identity. An example of a dispersive object type is Customer, which can be partitioned Into PrivateCustomer and CorporateCustomer that are identified in different ways.
An object type is rigid if its instances cannot cease to be of that type without ceasing to exist (or altering their identity). Person is an example of a rigid object type, while Employee is not rigid. A segmentation is called rigid if all segment subclasses are rigid.
The most important categories of object types are:
- Kind
- A kind is a rigid sortal object type. Examples of kinds are
TextBookandPerson. - Role
- A role is a sortal object type R classifying all instances of a kind K that participate in a relationship (of a certain type A) with an instance of an object type O. Notice that R is a non-rigid subtype of K since its instances do not cease to exist when they happen to cease instantiating R because they no longer participate in a relationship of type A with an instance of type O. For instance,
Employeeis an example of a role since it is a sortal object type classifying all instances ofPersonthat participate in an employment relationship with an instance of typeEnterprise. - Role Mixin
- A role mixin is a dispersive object type that can be partitioned into a set of roles. For instance, the role mixin
Customercan be partitioned Into the rolesPrivateCustomerandCorporateCustomer.
In OE class models, we use the keywords ("stereotypes") «object base type» for kinds, «object role type» for roles, and «object role mixin type» for role mixins, as shown in the following model.

Attributes as Variables or Parameters
Composite Objects
Objects with Connection Points
2.1.2. Modeling Event Types
For simplicity, we often say "event" instead of "instantaneous event". We trust the reader's ability to disambiguate the intended meaning of "event": either denoting the general category of events or the specific category of instantaneous events.
All event types have the implicit attributes startTime, occurrenceTime, and duration, such that
duration = occurrenceTime − startTime.
For instantaneous events, such as user arrivals and departures, only their occurrence time is meaningful (their start time is the same as their occurrence time and their duration is zero).
It is important to understand that objects participate in events – this is a principle of foundational ontologies such as UFO. It implies that there are corresponding participation associations between an event type and its participating object types.
Event types are modeled in OE class diagrams in the form of class rectangles categorized with the ("stereotype") keyword «event type», as shown in the following example model:

This model includes the four event types arrival, departure, book borrowing and book return. While arrival and departure events have a library user as their only participating object, book borrowing and book return events have both a library user and one or more book copies as participants. The participation associations expressing these participations are shown with a blue line in the diagram above.
The multiplicity expression ∗ at the arrival and departure association ends states that a library user participates in zero or many arrival and departure events over time.
Notice that book borrowing and book return events represent corresponding activity end events since borrowing and returning books are, in fact, activities that take some time and, therefore, consist of an activity start event followed by an activity end event. Whenever we are not interested in considering their start event and their duration, we can reduce activities to their (instantaneous) end events, as in the model above.
While we model (types of) business events in business process (simulation) models, we may also want to model more low-level types of events in other kinds of models, such as messaging events, user interface events or software application system events.
Object Events and State Machines
2.1.3. Modeling Activity Types
It is important to distinguish between ongoing and completed activities. Only a completed activity corresponds to an event, since events need to have occurred (they need a value for their occurrence time attribute), so they are always in the past. As explained in (Guarino and Guizzardi 2024), an ongoing activity is an ongoing process.
Activity types have the implicit attributes startTime, occurrenceTime, and duration, where duration = occurrenceTime − startTime. Activities occur when they end/complete.
Activity types are modeled in OE class diagrams in the form of class rectangles categorized with the ("stereotype") keyword «activity type», as shown in the following example model:

This model includes the two activity types book lending and book take back, both of which have a library user and one or more book copies as their participating objects. Notice that activities of these two types have, in fact, a further participant: the library clerk performing them. For simplicity, we have abstracted away from their performer when modeling these activity types in the model above. A performer is a special type of resource required for performing an activity. While performers are 'active' resources, there may also be several 'passive' resources required for performing an activity. This is elaborated in the subsection on Resource-Constrained Activities below.
Activities are Composed of a Start Event and an End Event
Conceptually, an activity is a composite event that is composed of, and temporally framed by, a pair of start and end events. Consequently, whenever a model contains a pair of related start and end event types, like processing start and processing end in the model of a manufacturing workstation shown on the left-hand side of Figure 2-1 and Figure 2-2, they can be replaced with a corresponding activity type, like processing, as shown on the right-hand side.



It is obvious that applying this replacement pattern leads to a conceptual and visual simplification of the models concerned.


Resource-Constrained Activities
A resource-constrained activity is an activity that requires certain resources for being performed. Such an activity can only be started when the required resources are available and can be allocated to it. For instance, a book lending activity requires a service desk (with a computer) and a library clerk as its resources.
We can distinguish between ‘active’ (or performer) resources, such as human resources, robots or IT systems, which execute activities, and ‘passive’ resources, such as rooms or devices, which are used by performers for executing activities. At any point in time, a resource required for performing an activity may be available or not. A resource is not available, for instance, when it is busy or when it is out of order.
2.1.4. Modeling Participation Associations
When we model event and activity types along with object types in OE class models, we also have to model the special associations between them expressing the participation of objects in events and activities, like library users participating in arrival and departure events, or book copies participating in book lending and book take back activities, as shown with blue lines in the following diagram:
This model includes six participation associations:
- Exactly one library user participates in any arrival or departure event, as indicated by the multiplicity '1' shown at the library user association end.
- Exactly one library user participates in any book lending or book take back activity, as indicated by the multiplicity '1'.
- One or more book copies participate in any book lending or book take back activity, as indicated by the multiplicity '1..*'.
While the above three statements express the participant multiplicities shown at the association ends of the respective participant object types, there are also participation multiplicities shown at the association ends of the respective event/activity types. They can be stated as follows:
- A library user participates in zero or more arrival and departure events over time, as indicated by the multiplicity '*'.
- A library user participates in zero or more book lending and book take back activities over time, as indicated by the multiplicity '*'.
- A book copy participates in zero or more book lending and book take back activities over time, as indicated by the multiplicity '*'.
Notice that we have used the phrase "over time" in these participation multiplicity statements. It refers to the history populations of the event/activity classes involved.
Tauzovich (1991) has proposed a distinction between snapshot and history cardinality constraints in his Temporal Entity-Relationship modeling approach. We adopt this distinction for OE class models, where we allow for a snapshot multiplicity expression in the form of “S:m“, where m is a normal multiplicity expression (such as * or 0..1), in addition to the history multiplicity expression at the event/activity class side (or association end) of a participation association. For avoiding the cluttering of OE class diagrams, we assume that, by default, at the event/activity class side of a participation association, the snapshot multiplicity is zero-or-one (0..1). By convention, we only display an explicit snapshot multiplicity expression in an OE class diagram if it is different from the default (0..1).
However, in addition to these history participation multiplicities stating in how many events/activities an object may participate over time, we also need to be able to express snapshot participation multiplicities stating in how many events/activities an object may participate at a time. We can do this by adding a second multiplicity expression to the association end at the event/activity type side prefixed with "S:", as in the following diagram:

The snapshot participation multiplicity 'S:0..1' in this example can be verbalized as follows: a library user participates in at most one book lending activity at a time. Since this multiplicity is the most frequent type of snapshot participation multiplicity, it is assumed as the default (and not shown) in OE class models. Consequently, in the model above, since no snapshot participation multiplicities are shown, all of them have by default the multiplicity 0..1, as verbalized by the following statements:
- A library user participates in at most one arrival or departure event at a time.
- A library user participates in at most one book lending or book take back activity at a time.
- A book copy participates in at most one book lending or book take back activity at a time.
2.2. Making Conceptual Process Models
A conceptual process model should describe the relevant causal regularities of the problem domain in the form of event rules, providing one event rule for each type of event described in the conceptual information model. A conceptual event rule for an event type describes the state changes and follow-up events caused by events of that type. This includes describing in which temporal sequences events may occur, based on conditional and parallel branching.
A conceptual process model can be expressed textually in the form of a list or a table of event rule statements or visually in the form of an Object Event Graph or an Activity Network, which are two forms of DPMN Process Diagrams.
2.2.1. Modeling Causal Regularities with Event Rule Tables
Causal regularities can be described with the help of event rules, which express, for an event type E, the state changes and follow-up events caused by events of that type.
After identifying the relevant types of events of a problem domain, e.g., with the help of an OE class model, we can list the event rules for these event types in the form of a table like the following:
| ON | STATE CHANGES | FOLLOW-UP EVENTS |
|---|---|---|
| arrival | record that user has entered the library | book lending if user wants to borrow books book take back if user wants to return books |
| book lending | set status to LENDED for all lended book copies | departure |
| book take back | set status to AVAILABLE for all returned book copies | departure |
| departure | record that user has departed the library |
Notice that, for simplicity, we do not consider the case where a library user, after arriving at the library, departs some time later without returning or borrowing books (e.g., because she couldn't find any interesting book).
A follow-up event does often not happen immediately after the causing event, but only later after some kind of delay. For instance, after arriving at the library, a user may not immediately go to the service desk and return her due book copies, but rather first browse the newly arrived books shelf.
2.2.2. Modeling Causal Regularities with Object Event Graphs
Object Event Graphs (OEGs) extend the Event Graph diagram language of (Schruben 1983) by adding object rectangles containing declarations of typed object variables and state change statements, as well as gateway diamonds for expressing conditional and parallel branching.
The following OEG is based on the object and event type definitions of the OE class diagram shown in .

Notice that the short arrows leading from event circles to gateway diamonds, such as the arrow from the arrival event circle to the inclusive gateway diamond (representing an inclusive-disjunctive split), or from gateway diamonds to event circles, such as the arrow from the inclusive gateway diamond (representing an inclusive-disjunctive merge) to the departure event circle, have a different meaning than the long arrows coming in to, and going out from, event circles. The short arrows are just an auxiliary notation for connecting event circles and gateway diamonds, while the long arrows represent causation, which implies temporal precedence:
- Each book lending event, and each book take back event, must be preceded by a corresponding arrival event.
- Each departure event must be preceded by a corresponding book lending or book take back event.
2.2.3. Modeling Causal Regularities with Activity Networks
Object Event Graphs (OEGs) extend the Event Graph diagram language by adding object rectangles containing declarations of typed object variables and state change statements, as well as gateway diamonds for expressing conditional and parallel branching.
The following OEG is based on the object, event and activity type definitions of the OE class diagram shown in .

This model includes the two activity types book lending and book take back, both of which have a library user and one or more book copies as their participating objects.
Again, the long arrows represent causation, which implies temporal precedence:
- Each book lending activity, and each book take back activity, must be preceded by a corresponding arrival event.
- Each departure event must be preceded by a corresponding book lending or book take back activity.
Compare this to the "sequence flow" arrows in BPMN process models that are typically intended to represent workflow sequencing, which means that follow-up tasks are added to the task lists of the human performers in charge who decide when to start/perform the follow-up tasks. Our example of a public library business process is not a workflow process, since the start of follow-up activities is not controlled by their performers.
Chapter 3. Making Design Models for Information Systems
A design model defines a computational design (for an IS or for a simulation) based on a conceptual model. While a conceptual domain model is descriptive, describing the domain's structure (its entities and relationships) and dynamics, a design model is prescriptive, defining design artifacts.
Unlike a conceptual model, a design model is tailored towards the purpose of an IS, or a simulation, engineering project. Although the design model is independent of a specific technology platform, it is typically based on object-oriented (OO) modeling (e.g., with UML Class Diagrams). It can be implemented in different ways with any specific technology choice, typically using an OO programming approach.
An information design model is derived from a conceptual information model by choosing the design-relevant types of objects and events and enrich them with design details, while dropping other object types and event types not deemed relevant for the simulation design. Adding design details includes specifying property ranges as well as adding multiplicity and other types of constraints.
In á process design model, we refine a conceptual process model. We can do this by identifying those types of events that account for the causation of relevant state changes and follow-up events by triggering a causal regularity. Any event type modeled in the information model could potentially trigger a causal regularity.
For designing an information system (IS), it is essential to identify the types of business objects, business events and business activities that have to be represented and supported by the IS. This choice can be made on the basis of the conceptual domain model and the IS requirements provided by the project clients. In the case of our example problem, the public library, these types are:
- the business object types Book, BookCopy, LibraryUser and Person;
- the business event types Arrival and Departure;
- the business activity types BookLending and BookTakeBack.
Notice that in the design model, as is common in OO modeling, we use camel case notation for all type names.
The two event types Arrival and Departure would only be included in the design model, if it is required to record the arrival and departure times of library users, e.g., for getting statistics about the times they spend in the library. This can be achieved by having library users present their membership card to card readers at the entrance and exit. Each card reading would create a corresponding event record in the database of the library IS.
3.1. Information Design for IS Engineering
An information design model is derived from a conceptual information model by choosing the design-relevant types of objects and events and enrich them with design details, while dropping other object types and event types not deemed relevant for the simulation design. Adding design details includes specifying attribute ranges as well as adding multiplicity and other types of constraints.
As opposed to the underlying conceptual information model shown in Section 2.1.3, the following information design model provides attribute ranges, standard identifiers, mandatory value and key constraint declarations (by default, in UML, attributes are mandatory and single-valued).

Notice also the notation "/date" in the attribute compartments of the activity classes BookLending and BookTakeBack, where the slash prefix indicates that the attribute date is a derived attribute (its value can be automatically computed from the implicit occurrenceTime attribute).
The class model expressed above with the visual modeling language of OE class diagrams can also be expressed textually, following the syntax of KerML, in the following way:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | objectType Person {
attribute id : Integer {id};
attribute name : String;
attribute birthDate : Date;
attribute biography : String[0..1];
}
objectType LibraryUser specializes Person {
attribute userId : Integer {key};
attribute address : String;
}
eventType Arrival {
attribute libraryUser : LibraryUser;
}
eventType Departure {
attribute libraryUser : LibraryUser;
}
objectType Book {
attribute isbn : String {id};
attribute title : String;
attribute year : Integer;
attribute authors : Person[0..*];
}
enum BookCopyStatusEL {
AVAILABLE;
LENDED;
}
objectType BookCopy {
attribute id : Integer {id};
attribute isbn : String;
attribute status : BookCopyStatusEL;
}
activityType BookLending {
attribute id : Integer {id};
attribute date : Date;
attribute libraryUser : LibraryUser;
attribute bookCopies : BookCopy[1..*];
}
activityType BookTakeBack {
attribute id : Integer {id};
attribute date : Date;
attribute libraryUser : LibraryUser;
attribute bookCopies : BookCopy[1..*];
} |
3.2. Process Design for IS Engineering
In a process design model for a process-supportive IS, we refine a conceptual process model by adding all details needed for obtaining a computationally complete definition of the business processes to be supported. While the arrows in conceptual process models represent the causation of follow-up events/activities, the arrows in process design models represent workflow sequencing.
An important question in process design is whether the process consist of activities that have to be performed in a certain order, like a workflow process, or that may be performed in any order, like a flexible business process. In the former case, the workflow sequencing of activities has to be defined in a suitable process model, while in the latter case, workflow sequencing is not possible and it is sufficient to define the state changes that come with the performance of activities, either in a process model without arrows or in an extended version of the underlying OE class model.
3.2.1. Designing Flexible Business Processes
In our example of a public library process shown in the following conceptual process model diagram, there are only two types of activities, book lending and book take back, which may be performed in any order, so we deal with a flexible business process.
Notice that the sequencing from arrival events to book lending and book take back activities in this conceptual process model expresses causation and the implied temporal precedence, but does not mean that there is a corresponding workflow sequencing such that on arrival, a book lending or book take back activity can be added to the task list of the library clerk in charge. Rather, since the start times of any book lending and book take back activities are controlled by the library user going to the service desk, and not by the library clerk, there is no workflow sequencing and, consequently, we have to drop the work sequence flow arrows in the process design model, as shown in the following diagram:

This process design model, using the names (of types, attributes and operations) defined in the information design model shown in Section 3.1, defines in the attached object rectangles for all event circles and activity rectangles:
- variable names and bindings of these variables to parameter values (e.g., by the equality u = a.user assigning the user object reference of the expression a.user to the variable u),
- state change statements that will be executed when a corresponding event occurs or when a corresponding activity completes.
These variable definitions and state change statements can also be expressed in onEvent and onActivityEnd operations in corresponding event and activity classes. In this way, they can be added to the OE class model from Section 3.1 by adding these operations to the classes concerned, resulting in the following model:

3.2.2. Designing Workflow Processes
In a workflow process, an activity to be performed by a specific organizational role is scheduled by adding a corresponding task to the task list of that role. This form of task scheduling provides the operational meaning of sequence flow arrows in business process design models
In a workflow process design model, activity rectangles represent either human activities or IS service operations. In the case of human activities, the process design model should specify the organizational role that is in charge of performing them, e.g., by annotating the activity rectangle with the name of the role. For instance, the model shown in Figure 3-3 specifies the role LibraryClerk as being in charge of performing MakeRecommendation activities.

Chapter 4. Making Design Models for Discrete Event Simulations
A simulation design model defines a computational design for a simulation based on a conceptual model. Unlike the conceptual domain model, the design is tailored towards the purpose of the simulation project (e.g., for answering certain research questions in a social system analysis project or in a technical system engineering project, or for teaching certain facts about a system in an educational simulation project). Although the design model is independent of a specific technology platform, it is typically based on OO modeling (e.g., with UML diagrams). It can be implemented in different ways with any specific technology choice, typically using an OO programming approach.
A simulation design model for simulating an organization may also be based on an IS design model for that organization. We can distinguish two different cases:
- If the purpose is to compute certain statistics, then an offline simulation design model is made from the IS design model by dropping all elements that are not relevant for the purpose of the simulation to be built. For instance, if the purpose of our library simulation is to compute the organizational performance statistics of average and maximal length of the waiting line at the service desk, then we can abstract away from the object type Person and the attributes Book::title, Book::year, and Book::authors described in the domain model shown in Section 2.1.2. We may even drop the object types Book and BookCopy altogether, if we just count the number of books lended and taken back in the simulation design model.
- If the purpose is to support operational decision making, then a digital twin design model has to be made as an extension of the IS design model. For instance, if the purpose of our library simulation is to support making decisions like testing if a library clerk can take a one hour break without taking the risk of overlong waiting lines at the service desk, then a digital twin of the library, including all elements of the library IS model, has to be made.
4.1. Making Information Design Models for DES Engineering
In addition to the general information modeling issues, there are also a few issues, which are specific for simulation modeling:
- The information design model must designate attributes representing state variables that are subject to random variation, so they can be considered as random variables with an underlying probability distribution that is sampled by a corresponding method stereotyped «rv» for categorizing it as a random variate sampling method. The underlying probability distribution can be indicated in the model diagram by appending a symbolic expression, denoting a distribution (with parameter values), to the method definition clause. For instance, U(1,6) may denote the uniform distribution with lower bound 1 and upper bound 6, while Exp(1.5) may denote the exponential distribution with event rate 1.5.
- The information design model must distinguish between exogenous and caused (or endogenous) event types. For any exogenous event type, the recurrence of events of that type must be specified, typically in the form of a random variable, but in some cases it may be a constant (like 'on each Monday'). The recurrence defines the elapsed time between two consecutive events of the given type (their inter-occurrence time). It can be specified within the event class concerned in the form of a special operation with the predefined name 'recurrence' and normally annotated with a probability distribution expression.
- The information design model must specify a duration() function for all activity classes. This function is invoked when a new activity is created during a simulation run for computing the value of its duration attribute. Normally, the duration() function represents a random variable, to be indicated by the stereotype «rv» and by appending a probability distribution annotation such as Exp(1.5).
- If the simulation is to deal with objects in space, the design model must be based on a choice of space model: one-dimensional (1D) discrete space, two-dimensional (2D) discrete space (also called grid space), three-dimensional (3D) discrete space, and 1D/2D/3D continuous space. The chosen space model implies a corresponding form of spatial positions (or locations): a 1-, 2- or 3-tuple of integers or decimal numbers.
Following these rules, by extending the IS information design model (from Section 3.1) we obtain the following model:

4.2. Making Process Design Models for DES Engineering
In a process simulation design model, we refine a conceptual process model by adding all details needed for obtaining a computationally complete process simulation model that can be directly transformed into simulation code.

Part II. Event-Based Simulation
Event-Based Simulation (ES) is the most fundamental form of Discrete Event Simulation (Pegden 2010). The ES paradigm has been pioneered by SIMSCRIPT (Markowitz, Hausner & Karr 1962) and later formalized by Event Graphs (Schruben 1983).
ES uses state variables for modeling a system’s state and event scheduling with a Future Events List for modeling its dynamics. An implementation-agnostic definition of ES is provided by Event Graphs, which define graphically how an event triggers
- (possibly conditional) state changes (in the form of variable value assignments) and
- (possibly conditional) follow-up events.
According to Pegden (2010), in ES, the system under investigation is viewed as a series of instantaneous events that change its state over time. The modeler “defines the events in the system and models the state changes that take place when those events occur”. More precisely, the modeler defines the types of events that cause state changes and/or follow-up events.
Pegden also explains that in ES,
- a simulation creates events that are supposed to occur in the future (called future events),
- future events are scheduled (using an Event Scheduling mechanism),
- time advances to the time of the next event (next-event time progression),
- the series of events corresponds to a sequence of state transitions of a transition system where the “transition logic” of each event type is specified in the form of a procedure definition (often called event routine).
Event routines can be expressed in a programming-language-independent way using pseudo code as in (Pegden 2010), or in a (simulation) programming language. In an object-oriented programming approach, it is natural to define an event routine as a method of the class defining the event type.
Pegden does not make any attempt to clarify the philosophical nature of (types of) events and their “transition logic”. Philosophically, (1) all events have participants, which are the objects that participate in them; (2) the combination of an event type and its event routine results in an event rule of the form
ON event PERFORM state changes SCHEDULE follow-up events
representing a causal regularity.
Object Event Simulation (OES) extends ES by adding the modeling concepts of objects.
Chapter 5. Event-Based Simulation with and without Objects
5.1. Event Graphs: Event-Based Simulation without Objects
When Event-Based Simulation (ES) was developed in the 1960's, pioneered by SIMSCRIPT, the software engineering paradigm of Object-Oriented (OO) modeling and programming was not yet available. Therefore, the real-world objects of a system under investigation have not been modeled as objects, but rather the relevant characteristics of the (objects of) the system have been modeled in the form of state variables.
Event Graphs (EGs) have been proposed as a diagram language for making ES models by Schruben (1983). A node in an EG is visually rendered as a circle and represents a typed event variable (such that the node's name is the name of the associated event type). An event circle may be annotated with state change statements in the form of state variable assignments. An arrow (or directed edge) between two event circles (nodes) represents (a) the causation of a follow-up event in the case of a conceptual process model, or (b) the scheduling of a follow-up event according to the event scheduling paradigm in the case of a process simulation design model.
An Event Graph defining an ES model for a service desk system with one state variable (Q for queue length) and two event types (Arrival and Departure) is shown in the following diagram:

This model specifies three event rules, one for each event circle:
- On each initial event (the leftmost unnamed circle), the variable Q is initialized by setting it to 0, and then an Arrival event is scheduled to occur immediately.
- When an Arrival event occurs, the variable Q is incremented by 1 and, if Q is equal to 1, a Departure event is scheduled with a delay provided by invoking the function serviceTime (representing a random variable); in addition (since Arrival events are exogenous), a new Arrival event is scheduled with a delay provided by invoking the function recurrence (also representing a random variable).
- When a Departure event occurs, the variable Q is decremented by 1 and, if Q is greater than 0 (that is, if the queue is non-empty), another Departure event is scheduled with a delay provided by invoking the function serviceTime.
In Schruben's original notation for EGs used above:
There is an initial event (the left-most unnamed circle in the example EG above) creating the initial state with the help of one or more initial state variable assignments (here Q := 0) and triggering the real start event (here: Arrival). In our improved notation for EGs, we will drop this element in favor of getting simpler diagrams and assume that the initial state definition is taken care of separately and is not part of a process model diagram.
The recurrence of a start event (here: Arrival) is explicitly modeled with the help of a recursive arrow (going from the Arrival event circle to the Arrival event circle). In our improved notation for EGs, this recursive arrow is dropped assuming that the type definition of exogenous start events includes a recurrence function that is invoked by a simulator for automatically scheduling recurrent exogenous events (like Arrival).
Conditional event scheduling arrows are indicated by annotating the arrows with a condition in parenthesis, as shown above for the arrow between Arrival and Departure and the (reverse) arrow between Departure and Arrival. In our improved notation for EGs, we replace the parenthesis with brackets and use BPMN's notation for conditional "sequence flow" arrows with a mini-diamond at the arrow's start as shown below.
The same service desk model is shown in the following diagram using the improved notation resulting from these three simplifications/modifications:

Notice that in our improved notation for EGs, we use a prefix "+" for delay expressions, e.g., writing "+serviceTime()" instead of "serviceTime()" as an annotation of the event scheduling arrow between Arrival and Departure, for better indicating that the expression represents a scheduling delay. Notice also that, to a great extent, we use the visual notation of BPMN, but not its semantics (e.g., we do not use BPMN's visual distinction between "Start" and "Intermediate" events).
EGs provide a visual modeling language with a precise semantics that captures the fundamental event scheduling paradigm. However, EGs are a rather low-level DES modeling language: they lack a visual notation for (conditional and parallel) branching, do not support object-oriented state structure modeling (with attributes of objects taking the role of state variables) and do not support the concept of activities.
5.2. Object Event Graphs: Event-Based Simulation with Objects
Classical Event-Based Simulation (ES) can be extended in a natural way by adding the modeling concept of objects, such that the characteristics of real-world objects can be captured by the attributes of model objects instead of using state variables. The resulting simulation paradigm is called Object Event Simulation (OES).
In this section, summarizing (Wagner 2020), we show how to extend Event Graphs by adding the modeling concept of objects, resulting in Object Event Graphs. The modeling concept of objects (as instances of classes) has been pioneered by Dahl and Nygaard (1967) in their simulation programming language Simula, which initiated the development of the Object-Oriented (OO) modeling and programming paradigm in Software Engineering.
The following basic DPMN diagram shows an OEG defining a process pattern that is instantiated by the above discrete event process example.

This process model is based on the following Object Event (OE) class model:

Notice that the multiplicity 1 (standing for "exactly one") at the association end touching the object class WorkStation expresses the constraint that exactly one workstation must participate in any event of one of the associated types (PartArrival, ProcessingStart, or ProcessingEnd), while the multiplicity 0..1 (standing for "at most one") at the other association ends (touching one of the three event classes) expresses the constraint that, at any moment, a workstation participates in at most one PartArrival event, in at most one ProcessingStart event, and in at most one ProcessingEnd event. Notice that a further constraint should be added: at any moment, a workstation must not participate in both a ProcessingStart and a ProcessingEnd event.
An OEG specifies a set of chained event rules, one rule for each event circle of the model. The above OEG specifies the following three event rules:
- On each PartArrival event, the inputBufferLength attribute of the associated WorkStation object is incremented and if the workstation's status attribute has the value AVAILABLE, then a new ProcessingStart event is scheduled to occur immediately.
- When a ProcessingStart event occurs, the associated WorkStation object's status attribute is changed to BUSY and a ProcessingEnd event is scheduled with a delay provided by invoking the processingTime function defined in the ProcessingStart event class.
- When a ProcessingEnd event occurs, the inputBufferLength attribute of the associated WorkStation object is decremented and if the inputBufferLength attribute has the value 0, the associated WorkStation object's status attribute is changed to AVAILABLE. If the inputBufferLength attribute has a value greater than 0, a new ProcessingStart event is scheduled to occur immediately.
An OEG can be reduced to an Event Graph by replacing the attributes of its object types with corresponding variables. Thus, the OEG diagram language is a conservative extension of the Event Graph diagram language.
Part III. Activity-Based Simulation and Activity Networks
Activity-Based Simulation is a form of DES where the concept of activities is used in addition to the basic concept of instantaneous events. A simple Activity Network (AN) is obtained from an OEG by adding activity nodes in the form of rectangles with rounded corners, as shown in the following example:

Chapter 6. Design Modeling of Simple Activities
Like in a conceptual model, also in a design model, a pair of corresponding activity start event and end event circles, like ProcessingStart and ProcessingEnd in the source models shown in Figure 6-1 and Figure 6-2, can be replaced with a corresponding activity rectangle, like Processing, as in the target models shown in these figures.
Extending basic OE class design models by adding activity types



In the case of an OE class design model, this replacement pattern implies allocating all features (attributes, associations and operations) of the classes defining the start and the end event type in the class defining the corresponding activity type, possibly with renaming some of them. In the example of Figure 6-1, there is only one such feature: the class-level operation ProcessingStart::processingTime, which is allocated to Processing and renamed to time.
Extending Object Event Graphs by adding Activity rectangles


In the case of a process design model, the rewrite pattern implies that an Event circle pair consisting of an Event circle intended to represent activity start events and an Event circle intended to represent related activity end events, with an event scheduling arrow from the start to the end Event circle annotated by a delay expression, is replaced by an Activity rectangle such that:
- All Data Objects attached to the end Event circle get attached to the Activity rectangle (since an activity occurs when it it is completed).
- All event scheduling arrows going out from the end Event circle are turned into event scheduling arrows going out from the Activity rectangle.
- All start event scheduling arrows are replaced with corresponding activity scheduling arrows having an additional creation parameter assignment for the duration of a scheduled activity, which is set to the delay expression defined for the end event scheduling arrow. In the example above, the duration parameter in the annotation of the two activity scheduling arrows is set to
Processing::time()in the target diagram, which is the same as the delayProcessingStart::processingTimein the source diagram. - When the start Event circle has one or more attached Data Objects or any outgoing event scheduling arrow that does not go to the end Event circle, then a start Event circle has to be included in the Activity rectangle for attaching the Data Object(s) and as the source of the outgoing event scheduling arrow(s).
This Activity-Start-End Rewrite Pattern, which can also be applied in the inverse direction, replacing an Activity rectangle with an Event circle pair, defines the meaning of an Activity rectangle in a DPMN diagram. It allows reducing a DPMN-AN diagram with Activity rectangles to an Object Event Graph (a basic DPMN diagram without Activity rectangles).
Notice that, like the source model, also the target model of Figure 6-2 specifies three event rules:
- On each PartArrival event, the arrived part is added to the workstation's input buffer and if the workstation's status is AVAILABLE, then a new Processing activity is scheduled to start immediately with a duration provided by invoking the time function defined in the Processing activity class.
- When a Processing activity starts, the workstation's status is changed to BUSY.
- When a Processing activity ends, the processed part is removed from the input buffer and, if the input buffer is not empty, a new Processing activity is scheduled to start immediately, otherwise (if the input buffer is empty) the workstation's status is changed to AVAILABLE.
An alternative process design model of the single workstation system
Based on the same information design model, shown in the target model of Figure 6-1, we can make another process design model of the single workstation system as an alternative to the target model of Figure 6-2. This alternative model makes it more clear that a workstation is, in fact, an exclusive resource of its processing activity. The concepts of resources and resource-constrained activities are discussed in the following sections, and in Section 7.2, it is shown how to simplify the basic DPMN model of Figure 6-3 by using the higher-level modeling elements introduced in DPMN-AN.

Chapter 7. Resource-Constrained Activities
A Resource-Constrained Activity is an activity that requires certain resources for being executed. Such an activity can only be started when the required resources are available and can be allocated to it.
We can distinguish between ‘active’ (or performer) resources, such as human resources, robots or IT systems, which execute activities, and ‘passive’ resources, such as rooms or devices, which are used by performers for executing activities. At any point in time, a resource required for performing an activity may be available or not. A resource is not available, for instance, when it is busy or when it is out of order.
Resources are objects of a certain type. The resource objects of an activity include its performer, as expressed in the diagram shown in Figure 7-1. While in the real-world, any activity has a performer, a conceptual domain model or a simulation design model may abstract away from the performer of an activity.
For instance, a consultation activity may require a consultant and a room. Such resource cardinality constraints are defined at the type level. When defining the activity type Consultation, these resource cardinality constraints are defined in the form of two mandatory associations with the object types Consultant and Room such that both associations' ends have the multiplicity 1 ("exactly one"). Then, in a simulation run, a new Consultation activity can only be started, when both a Consultant object and a Room object are available.
In an OE Class Diagram, an object type that has a resource status attribute and is the range of both a Resource Role and a Resource Pool property can be viewed as a resource type.
Activity Networks (ANs) extend OEGs by adding activity nodes (in the form of rectangles with rounded corners) and Resource-Dependent Activity Scheduling (RDAS) arrows.
For all types of resource-constrained activities, or, more precisely, for all activity nodes of an AN, a simulator can automatically collect the following statistics:
- Throughput statistics: the numbers of enqueued and dequeued planned activities, and the numbers of started and completed activities.
- Queue length statistics: the average and maximum length of its queue of planned activities.
- Cycle time statistics: the minimum, average and maximum cycle time, which is the sum of the waiting time and the activity duration.
- Resource utilization statistics: the percentage of time each resource object involved is busy with an activity of that type.
In addition, a simulator can automatically collect the percentage of time each resource object involved is idle or out-of-order.

For modeling resource-constrained activities, we need to define their types. As can be seen in Figure 7-2, a resource-constrained activity type is composed of
- a set of properties and a set of operations, as any entity type,
- a set of resource roles, each one having the form of a reference property with a name, an object type as range, and a multiplicity that may define a resource cardinality constraint like, e.g., "exactly one resource object of this type is required" or "at least two resource objects of this type are required".
The resource roles defined for an activity type may include the performer role.

These considerations show that a simulation language for simulating activities needs to allow defining activity types with two kinds of properties: ordinary properties and resource roles. At least for the latter ones, it must be possible to define multiplicities for defining resource cardinality constraints. These requirements are fulfilled by OE Class Diagrams where resource roles are defined as special properties categorized by the stereotype «resource role» or, in short, «rr».
The extension of basic OEM/DPMN by adding the concepts needed for modeling resource-constrained activities (in particular, resource roles with constraints, resource pools, and resource-dependent activity scheduling arrows) is called OEM/DPMN-AN.
7.1. Conceptual Modeling of Resource-Constrained Activities
Modeling resource-constrained activities has been a major issue in the field of Discrete Event Simulation (DES) since its inception in the nineteen-sixties, while it has been neglected and is still considered an advanced topic in the field of Business Process Modeling (BPM). The concept of resource-constrained activities is at the center of both DES and BPM. But both fields have developed different, and even incompatible, concepts of business process simulation.In the DES paradigm of Processing Networks, Gordon (1961) has introduced the resource management operations Seize and Release in the simulation language GPSS for allocating and de-allocating (releasing) resources. Thus, GPSS has established a standard modeling pattern for resource-constrained activities, which has become popular under the name of Seize-Delay-Release indicating that for simulating a resource-constrained activity, its resources are first allocated ("seized"), and then, after some delay representing the duration of the simulated activity, they are de-allocated ("released").
Resource roles, process owners and resource pools
As an illustrative example, we consider a hospital consisting of medical departments where patients arrive for getting a medical examination performed by a doctor. A medical examination, as an activity, has three participants: a patient, a medical department, and a doctor, but only one of them plays a resource role: doctors. This can be indicated in an OE Class Diagram by using the stereotype «resource role» for categorizing the association ends that represent resource roles, as shown in Figure 7-3.

Notice that both the event type patient arrivals and the activity type examinations have a (mandatory functional) reference property process owner. This implies that both patient arrival events and examination activities happen at a specific medical department, which is their process owner in the sense that it owns the process types composed of them. A process owner is called "Participant" in BPMN (in the sense of a collaboration participant) and visually rendered in the form of a container rectangle called "Pool".
In Figure 7-3, the resource role of doctors corresponds to the performer role. In BPMN, Performer is considered to be a special type of resource role. According to (BPMN 2011), a performer can be "a specific individual, a group, an organization role or position, or an organization".[1]In BPMN, Performer is specialized into the HumanPerformer of an activity, which is, in turn, specialized into PotentialOwner denoting the "persons who can claim and work" on an activity of a given type. "A potential owner becomes the actual owner [...] by explicitly claiming" an activity. Allocating a human resource to an activity by leaving the choice to those humans that play a suitable resource role is characteristic for workflow management systems, while in traditional DES approaches to resource handling, as in Arena, Simio and AnyLogic, (human) resources are assigned to a task (as its performer) based on certain policies.
Thus, the term "performer" subsumes several types of performers. We will, by default, use it in the sense of a human performer.
One of the main reasons for considering certain objects as resources is the need to collect utilization statistics (either in an operational information system, like a workflow management system, or in a simulation model) by recording the use of resources over time (their utilization) per activity type. By designating resource roles in information models, these models provide the information needed in simulations and information systems for automatically collecting utilization statistics.
In the hospital example, a medical department, as the process owner, is the organizational unit that is responsible for reacting to certain events (here: patient arrivals) and managing the performance of certain processes and activities (here: medical examinations), including the allocation of resources to these processes and activities. For being able to allocate resources to activities, a process owner needs to manage resource pools, normally one for each resource role of each type of activity (if pools are not shared among resource roles). A resource pool is a collection of resource objects of a certain type. For instance, the three X-ray rooms of a diagnostic imaging department form a resource pool of that department.
Resource pools can be modeled in an OE Class Diagram by means of special associations between object classes representing process owners (like medical departments) and resource classes (like doctors), where the association ends, corresponding to collection-valued properties representing resource pools, are stereotyped with «resource pool», as shown in Figure 7-3. At any point in time, the resource objects of a resource pool may be out of order (like a defective machine or a doctor who is not on schedule), busy or available.
A process owner has special procedures for allocating available resources from resource pools to activities. For instance, in the model of Figure 7-3, a medical department has the procedure "allocate a doctor" for allocating a doctor to a medical examination. These resource allocation procedures may use various policies, especially for allocating human resources, such as first determining the suitability of potential resources (e.g., based on expertise, experience and previous performance), then ranking them and finally selecting from the most suitable ones (at random or based on their turn). See also (Arias et al 2018).
The conceptual process model shown in Figure 7-4 is based on the information model above. It refers to a medical department as the process owner, visualized in the form of a Pool container rectangle, and to doctor objects, as well as to the event type patient arrivals and to the activity type examinations.

This process model describes two causal regularities in the form of the following two event rules, each stated with two bullet points: one for describing all the state changes and one for describing all the follow-up events brought about by applying the rule.
When a new patient arrives:
- if a doctor is available, then she is allocated to the examination of that patient; otherwise, a new planned examination is queued up;
- if a doctor has been allocated, then start an examination of the patient.
When an examination is completed by a doctor:
- if the queue of planned examinations is empty, then the doctor is released;
- otherwise, the next planned examination by that doctor is scheduled to start immediately.
These conceptual event rules describe the real-world dynamics of a medical department according to business process management decisions. Changes of the waiting line and (de-)allocations of doctors are considered to be state changes (in the, not necessarily computerized, information system) of the department, as they are expressed in Data Object rectangles, which represent state changes of affected objects caused by an event in DPMN.
Notice that the model of Figure 7-4 abstracts away from the fact that after allocating a doctor, patients first need to walk to the room before their examination can start. Such a simplification may be justified if the walking time can be neglected or if there is no need to maximize the productive utilization of doctors who, according to this process model, have to wait until the patient arrives at the room. Below, this model is extended for allowing to allocate rooms and doctors such that patients have to wait for doctors, and not the other way around.
Switching roles: doctors as patients
The same person who is a doctor at a diagnostic imaging department may be treated as a patient of that department. It's a well-known fact that in the real world people may switch roles and may play several roles at the same time, but many modeling approaches/platforms fail to admit this. For instance, the simulation language (SIMAN) of the well-known DES modeling tool Arena does not treat resources and processing objects ("entities") as roles, but as strictly separate categories. This language design decision was a meta-modeling mistake, as admitted by Denis Pegden, the main creator of SIMAN/Arena, in (Drogoul et al 2018) where he says "it was a conceptualization mistake to view Entities and Resources as different constructs".
In Figure 7-5, the above model is extended by categorizing the classes doctors and patients as «role type» classes and adding the «kind» class people as a supertype of doctors and patients, we create the possibility that a person may play both roles: the role of a doctor and the role of a patient, albeit not at the same time. The object type categories «kind» and «role type» have been introduced to conceptual modeling by Guizzardi (2005).

Queueing planned activities
Whenever an activity is to be performed but cannot start due to a required resource not being available, the planned activity is placed in a queue as a waiting job. Thus, in the case of a medical examination of a patient, as described in the model of Figure 7-5, the waiting line represents, in fact, a queue of planned examinations (involving patients), and not a queue of waiting patients.
This consideration points to a general issue: modeling resource-constrained activities implies modeling queues of planned activities, while there is no need to consider (physical) queues of (physical) objects. Consequently, even if a real-world system includes a physical queue (of physical objects), an OEM-A model may abstract away from its physical character and consider it as a queue of planned activities (possibly including pre-allocated resources). While a physical queue implies that there is a maximum capacity, a queue of planned activities does not imply this. For instance, when a medical department does not require patients to queue up in a waiting area for obtaining an examination, but accepts their registration for an examination by phone, the resulting queue of waiting patients is not a physical queue (but rather a queue of planned examinations) and there is no need to limit the number of waiting patients in the same way as in the case of queuing up in a waiting area with limited space.
A planned activity can only start, when all required resources have been allocated to it. Thus, a planned examination of a patient can only start, when both a room and a doctor have been allocated to it. Let's assume that when a patient p arrives, only a room is available, but not a doctor. In that case, the available room is allocated to the planned examination, which is then placed in a queue since it still has to wait for the availability of a doctor. Only when a doctor becomes available, e.g., via the completion of an examination of another patient or via an arrival of a doctor, the doctor can be allocated as the last resource needed to start the planned examination of patient p.
As a consequence of these considerations, the waiting line of a medical department modeled in Figure 7-5 as an ordered collection of patients is renamed to planned walks in Figure 7-6. In addition, a property planned examinations, which holds an ordered collection of patient-room pairs, is added to the class medical departments. These model elements reflect the hospital's business process practice to maintain a list of patients waiting for the allocation of a room to walk to and a list of planned examinations, each with a patient waiting for a doctor in an examination room.
Decoupling the allocation of multiple resources
For being more realistic, we consider the fact that patients first need to be walked by nurses to the room allocated to their examination before the examination can start. Thus, in the model of Figure 7-6, we add a second activity type, walks to room, involving people (typically, nurses and patients) walking to an examination room.


This process model describes three causal regularities in the form of the following three event rules:
When a new patient arrives:
- if a room and a nurse are available, they are allocated to the walk of that patient to that room, otherwise a new planned walk is placed in the corresponding queue;
- if a room has been allocated, then the nurse starts walking the patient to the room.
When a walk of a patient and nurse to a room is completed:
- if there is still a planned walk in the queue and a room is available, then the room is allocated and the nurse is re-allocated to the walk of the next patient to that room.
if a doctor is available, she is allocated to the examination of that patient, else a new planned examination of that patient is queued up; - if a doctor has been allocated, then the examination of that patient starts
if the nurse has been re-allocated, she starts walking the next patient to the allocated room.
- if there is still a planned walk in the queue and a room is available, then the room is allocated and the nurse is re-allocated to the walk of the next patient to that room.
When an examination of a patient is completed by a doctor in a particular room:
- if there is still a planned examination (of another patient in another room), then re-allocate the doctor to that planned examination, else release the doctor;
if the waiting line is not empty, re-allocate the room to the next patient, else release the room; - if the doctor has been re-allocated to a planned examination, that examination starts;
if the room has been re-allocated to another patient, that patient starts walking to the room.
- if there is still a planned examination (of another patient in another room), then re-allocate the doctor to that planned examination, else release the doctor;
Notice that the process type described in Figure 7-7 does not consider the fact that doctors have to walk to the examination room too, which could be modeled by adding a doctors' walks to room Activity rectangle after the patients' walks to room Activity rectangle.
For being able to collect informative utilization statistics, it is required to distinguish the total time a resource is allocated (its 'gross utilization') from the time it is allocated for productive activities (its 'net utilization'). Thus, only examinations would be classified as productive activities, while walks to room would rather be considered a kind of set-up activities.
Re-engineering the process type by centralizing the re-allocation of resources
In the process type described in Figure 7-7, the re-allocation of released resources is handled in the event rules of activity end events:
- when a nurse's and patient's walk to a room ends, the nurse is free to be re-allocated; so if there is another planned walk and a room is available, the nurse is re-allocated to a walk of the next patient to that room;
- when an examination ends, its resources (a doctor and a room) are re-allocated, if planned activities are waiting for them.
This approach requires that the same re-allocation logic is repeated in the event rules of all activity types associated with that type of resource, implying that all performers involved would have to know and execute the same re-allocation logic. It is clearly preferable to centralize this logic in a single event rule, which can be achieved by introducing release resource request events following activities that do not need to keep resources allocated, as shown in Figure 7-8 where the re-allocation of doctors and rooms is decoupled from the examination activities and centralized (e.g., in a special resource management unit) by adding the two event types room release requests and doctor release requests modeling simultaneous events that follow examinations.

This process model describes an improved business process with six event rules:
When a new patient arrives:
- if a room and a nurse are available, they are allocated to the walk of that patient to that room, otherwise a new planned walk is placed in the corresponding queue;
- if a room has been allocated, then the nurse starts walking the patient to the room.
When a walk of a patient and nurse to a room is completed:
- if a doctor is available, she is allocated to the examination of that patient, else a new planned examination of that patient is queued up;
- if a doctor has been allocated, then the examination of that patient starts; in addition, a nurse release request is issued.
When a nurse release request has been issued:
- if the waiting line is not empty and a room is available, allocate the room and re-allocate the nurse to the next patient, else release the nurse;
- if the nurse has been re-allocated to another patient, she starts walking that patient to the room.
When an examination is completed:
- [no state change]
- a room release request is issued (e.g., by notifying a resource management clerk or the department's information system), and, in parallel, a doctor release request is issued.
When a room release request is received by a resource manager:
- if the waiting line is not empty and a nurse is available, allocate the nurse and re-allocate the room to the next patient, else release the room;
- if the room has been re-allocated to another patient, the nurse starts walking that patient to the room.
When a doctor release request is received by a resource manager:
- if there is still a planned examination (of another patient in another room), then re-allocate the doctor to that planned examination, else release the doctor;
- if the doctor has been re-allocated to a planned examination, that examination starts.
Notice that, in the general case, instead of scheduling several simultaneous release requests, each for a single resource, when an activity completes, a single joint release request for all used resources should be scheduled, allowing to re-allocate several of the released resources jointly.
Displaying the process owner and activity performers
The process owner and the involved performers can be displayed in an OEM process model by using a rectangular Pool container for the process owner and Pool partitions called Lanes for the involved activity performers, as shown in Figure 7-9. Notice that, as opposed to BPMN, where lanes do not have a well-defined meaning, but can be used for any sort of arranging model elements, DPMN Lanes represent organizational actors playing the resource role of performer.

Non-exclusive resources
In OEM, a resource is exclusive by default, that is, it can be used in at most one activity at the same time, if no other multitasking multiplicity is specified. For instance, in all information models above (e.g., in Figure 7-3), the participation associations between the resource classes rooms and doctors and the activity classes walks to room and examinations do not specify any multitasking multiplicity for the association end at the side of the activity class, but just the historical participation multiplicity of zero-to-many (∗) expressing that resources participate in zero or more activities over time.
OEM allows expressing multitasking multiplicities with the help of snapshot multiplicities of the form "S:m", where m is a multiplicity expression, added to the history multiplicity of the association end concerned.
A non-exclusive resource can be simultaneously used in more than one activity. The maximum number of activities, in which a non-exclusive resource can participate at the same time, is normally specified at the type level for all resource objects of that type using the upper bound of a multitasking multiplicity. In general, there may be cases where it should be possible to specify this at the level of individual resource objects. For instance, larger examination rooms may accommodate more examinations than smaller ones.
A resource can be exclusive with respect to all types of activities (which is the default case) or it can be exclusive with respect to specific types of activities. For instance, in the model of Figure 7-10, a multitasking multiplicity of 0..1 is defined both for the participation of rooms in walks and in examinations. This means a room can participate in at most one walk and in at most one examination at a time, which is a different business rule, allowing to walk patients to a room even if it is currently used for an examination, compared to the model of Figure 7-6, allowing to walk patients to a room only if it is currently not being used for an examination.

7.2. Resource-Constrained Activities in Simulation Design Models
In simulation design models, resource-constrained activities can be modeled in two ways:
- either abstracting away from the structure of resource object types and individual resource objects, and only representing a resource object type in the form of a named resource pool with a quantity (or counter) attribute holding the number of available resources, or
- explicitly representing resource object types and individual resource objects of that type as members of a collection representing a resource pool.
While the first approach is simpler, the second approach allows modeling various kinds of non-availability of specific resources (e.g., due to failures or due to not being in the shift plan).
For any resource object type Res, the three operations described in the following table are needed.
| Resource management operation | General meaning | Resource counter approach | Resource pool approach |
|---|---|---|---|
| isResAvailable | test if a resource of type Res is available and return true or false | test if the corresponding resource counter attribute has a value that is greater than 0 | test if the number of available resource objects in the resource pool is greater than 0 |
| allocateRes | allocate a resource object of type Res | decrement resource counter attribute | select (and return) a resource object from the set of available resource objects in the resource pool (using an allocation policy) and designate it as BUSY |
| releaseRes | de-allocate a resource object of type Res | increment resource counter attribute | take a resource object of type Res as argument and designate it as AVAILABLE |
In both approaches, it is natural to add these operations to the object type representing the process owner of the activities concerned, as in the models shown in Figure 7-11 and Figure 7-13.
In the first approach, for each resource object type in the conceptual model, a resource counter attribute is added to the object type representing the process owner and the conceptual model's resource object types are dropped.
In the second approach, the conceptual model's resource object types are elaborated by adding an enumeration attribute status holding a resource status value such as AVAILABLE or BUSY. For each resource object type, a collection-valued property (such as rooms or doctors) representing a resource pool is added to the object type representing the process owner.
A simple model with resource counters
Using the conceptual information model shown in Figure 7-3 as a starting point, we first rename all classes and properties according to OO naming conventions and replace each of the two (conceptual) operations allocate a room and allocate a doctor with a triple of isAvailable/allocate/release operations for the two resource object classes Room and Doctor in the MedicalDepartment class, where we also add the counter attributes nmrOfRooms and nmrOfDoctors. Then, the two resource object classes Room and Doctor are dropped. The result of this elaboration is the information design model shown in Figure 7-11.

Using the conceptual process model shown in Figure 7-4 as a starting point and based on the type definitions of the information design model of Figure 7-11, we get the following process design.
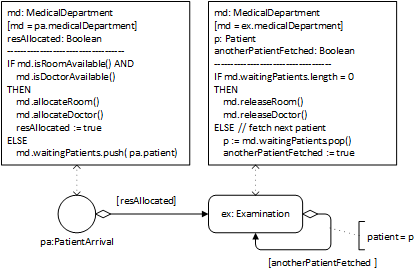
This process model defines the following two event rules.
| ON pa: PatientArrival |
|---|
| md : MedicalDepartment resAllocated : Boolean md := pa.medicalDepartment |
| IF md.isRoomAvailable() AND md.isDoctorAvailable() THEN md.allocateRoom(); md.allocateDoctor(); resAllocated := true ELSE md.waitingPatients.push( pa.patient); resAllocated := false |
| IF resAllocated SCHEDULE Examination( patient:=pa.patient, medicalDepartment:=md) |
| ON ex: Examination |
|---|
| md : MedicalDepartment anotherPatientFetched : Boolean p: Patient md := ex.medicalDepartment |
| IF md.waitingPatients.length = 0 THEN md.releaseRoom(); md.releaseDoctor(); anotherPatientFetched := false ELSE p := md.waitingPatients.pop(); anotherPatientFetched := true |
| IF anotherPatientFetched SCHEDULE Examination( patient:=p, medicalDepartment:=md) |
Notice that the event scheduling arrows of Figure 7-12, and also the SCHEDULE statements of the corresponding event rule tables, do not contain assignments of the duration of activities, since it is assumed that, by default, whenever an activity type has an operation duration(), the duration of activities of this type are assigned by invoking this operation.
A general model with resource objects as members of resource pools
In a more general approach, instead of using resource counter attributes, explicitly modeling resource object classes (like Room and Doctor) allows representing resource roles (stereotyped with «res») and resource pools (stereotyped with «pool») in the form of collections (like md.rooms and md.doctors) and modeling various forms of non-availability of resources (such as machines being defective or humans not being in the shift plan) with the help of corresponding resource status values (such as OUT_OF_ORDER). The result of this elaboration is the information design model shown in Figure 7-13.

For an OE class model, like the one shown in Figure 7-13, the following completeness constraint must hold: when an object type O (like Doctor) participates in a «res» association (a resource role association) with an activity type A (like Examination), the process owner object type of A (MedicalDepartment) must have a «pool» association with O.
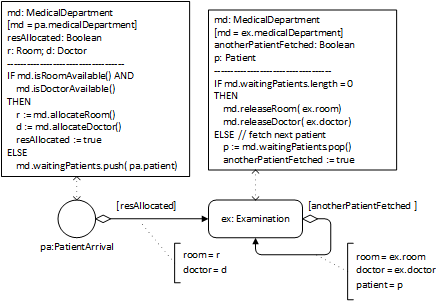
Extending OE Class Diagrams by adding a «resource type» category
The information design model of Figure 7-13 contains two object types, Room and Doctor, which are the range of resource role and resource pool properties (association ends stereotyped «res» and «pool»). Such object types can be categorized as «resource type» with the implied meaning that they inherit a resource status attribute from a pre-defined class Resource, as shown in Figure 7-16.
Resource
The introduction of resource types to OEM class models allows simplifying models by dropping the following modeling items from OE class models, making them part of the implicit semantics:
- the status attributes of object types representing resource types, which are implicitly inherited;
- the pre-defined enumeration ResourceStatusEL;
- the resource management operations isAvailable, allocate and release, which are implicitly inherited by any resource type; and
- the planned activity queues may possibly be implicitly represented for any resource-constrained activity type in the form of ordered multi-valued reference properties of its process owner object type.

Revisiting the manufacturing workstation example
A manufacturing workstation, or a "server" in the terminology of Operation Research, represents a resource for the processing activities performed at/by it. This was left implicit in the OE class model shown on the right-hand side of Figure 6-1. Using the new modeling elements (resource types, resource roles and resource pools), the processing activities of a workstation can be explicitly modeled as resource-constrained activities, leading to the OE class model shown in Figure 7-17 and to a more high-level and more readable process model compared to the process model of Figure 6-2.

Decoupling the allocation of multiple resources
In a simplified simulation design for the extended scenario (with patients and nurses first walking to examination rooms before doctors are allocated for starting the examinations) described by the conceptual models of Figure 7-6 and Figure 7-9, we do not consider the walks of doctors, but only the walks of nurses and patients. For simplicity, we drop the superclass people and associate the activity type WalkToRoom with the Patient and Nurse classes. The result of this elaboration is the information design model shown in Figure 7-18.

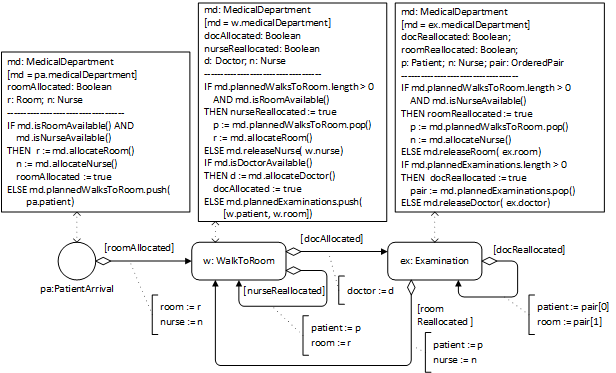
This process design model defines three event rules. Notice that the Examination event rule either re-allocates the doctor to the next planned examination and schedules it, if there is one, or it releases the doctor and re-allocates the room to the next planned walk-to-room and schedules it, if there is one.
Centralizing the re-allocation of resources
As shown before, in the conceptual process models of Figure 7-8 and Figure 7-9, the re-allocation of resources can be centralized with the help of resource release request events and the process owner and the involved performers can be displayed by using a Pool that is partitioned into Lanes for the involved activity performers, resulting in the model shown in Figure 7-20.
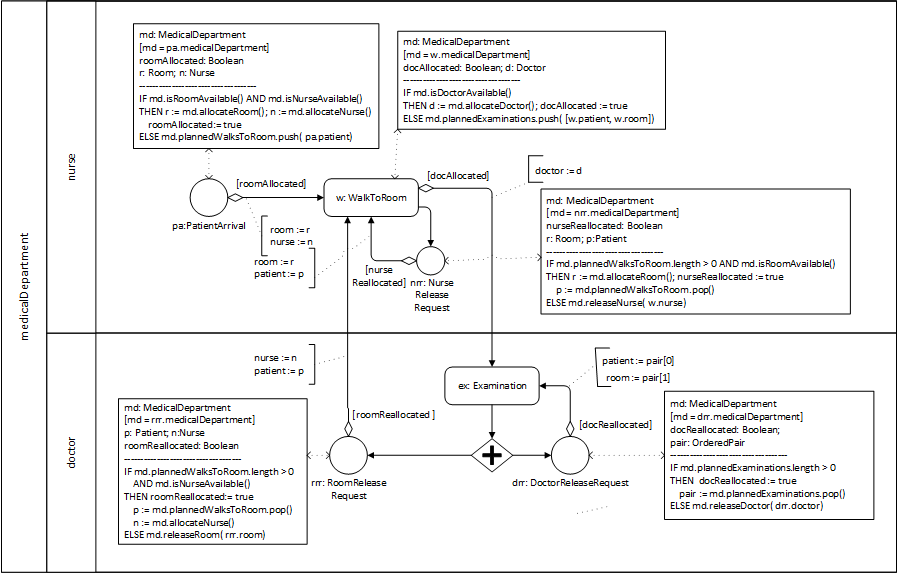
7.3. Introducing Resource-Dependent Activity Scheduling Arrows
The conceptual process model shown in Figure 7-9 and the process design model shown in Figure 7-20 exhibit a general pattern for modeling a sequence of two resource-constrained activities of types A1 and A2 shown in Figure 7-21. For describing this Allocate-Release Modeling Pattern, we assume that
- the process owner maintains queues for planned activities: q1 for for planned activities of type A1, and q2 for planned activities of type A2, both defined as queue-valued (i.e., ordered multi-valued) reference properties of the process owner in the underlying information model;
- the underlying information model specifies the sets of resources R1 and R2 required by A1 and A2;
- the set of resources required by A2 but not by A1 is denoted by R2−R1;
- the set of resources required by A1 and by A2 is denoted by R1∩R2.

We can describe the execution semantics of the Allocate-Release Modeling Pattern for the case of a succession of an activity of type A1 by another activity of type A2 in the following way:
- ON start event:
- If the resources R1 required by A1 are available, they are allocated; otherwise, a planned A1 activity is added to the task queue q1.
- If the resources R1 have been allocated, a new activity of type A1 is started.
- WHEN an activity of type A1 is completed:
- If available, the resources R2−R1 are allocated; otherwise, a planned A2 activity with reserved resources R1∩R2 is added to the task queue q2.
- If R2−R1 have been allocated, a new activity of type A2 (with resources R2−R1 and R1∩R2) is started. In addition, the release of R1−R2 is requested.
- ON release request for R1−R2:
- If q1 is not empty and the resources R1∩R2 required by both A1 and A2 are available, they are allocated and R1−R2 are re-allocated to head( q1); otherwise, R1−R2 are released.
- If the resources R1−R2 have been re-allocated, a new activity of type A1 is started.
- WHEN an activity of type A2 completes:
- There is no state change.
- An immediate release request for R2 is caused/scheduled.
- ON release request for R2:
- If R1∩R2 is nonempty: if q1 is not empty and the resources R1−R2 required by A1, but not yet allocated, are available, they are allocated and R1∩R2 are re-allocated to head( q1); otherwise, R1∩R2 are released. If q2 is not empty, then re-allocate R2−R1 to head( q2); otherwise, R2−R1 are released.
- If R1∩R2 have been re-allocated, a new activity of type A1 is started. If R2−R1 have been re-allocated, a new activity of type A2 is started.
Since the Allocate-Release Modeling Pattern defines a generic algorithm for scheduling resource-constrained activities as well as allocating and releasing resources, its (pseudo-)code does not have to be included in a DPMN Process Diagram, but can be delegated to an OE simulator supporting the resource-dependent scheduling of resource-constrained activities according to this pattern. This approach allows introducing new DPMN modeling elements for expressing the Allocate-Release Modeling Pattern in a concise way, either leaving allocate-release steps completely implicit, as in the DPMN Process Diagram of Figure 7-22, or explicitly expressing them, as in Figure 7-23.
The most important new DPMN modeling element introduced are Resource-Dependent Activity Scheduling (RDAS) arrows pointing to resource-constrained activities, as in Figure 7-22. These arrows are high-level modeling elements representing the implicit allocate-release logic exhibited in Figure 7-21. Thus, the meaning of the model of Figure 7-22 is provided by the model of Figure 7-21.

It is an option to display the implicit allocate-release steps with Allocate and Release rectangles together with simple control flow arrows, as between the start event circle and the Allocate R1 rectangle in Figure 7-23.

The meaning of the model of Figure 7-23 is the same as that of Figure 7-22, which is provided by the model of Figure 7-21. The fact that, using RDAS arrows, the allocate-release logic of resource-constrained activities does not have to be explicitly modeled and displayed in a process model shows the power of founding a process model on an information model, since the entire resource management logic can be expressed in terms of resource roles, constraints and pools in an information model. This is in contrast to the common approach of industrial simulation tools, such as Simio and AnyLogic, which require defining resource roles, constraints and pools as well as explicit allocate-release steps in the process model, in a similar way as shown in Figure 7-23.
The Standard Allocate-Release Algorithm
For each activity type, it has to be decided, if the resources required for a planned activity of that type are allocated at once or successively as soon as they become available. We call these two allocation policies Single-Step Allocation (SSA) and Multi-Step Allocation (MSA).
We can describe the Standard Allocate-Release Algorithm for the case of an event of type E succeeded by an activity of type A1 succeeded by another activity of type A2, with Ri and qi being the set of resource roles and the task queue of Ai, in the following way:
- WHEN an event e@t of type E occurs:
- A planned activity a of type A1 is created. If all R1 resources are available, they are allocated to a. Otherwise: (1) if MSA, then all available R1 resources are allocated to a; (2) a is added to the task queue q1.
- If all R1 resources have been allocated to a, it is started.
- WHEN an activity a1 of type A1 is completed:
- A planned activity a2 of type A2 is created. If all R2−R1 resources are available, they are allocated to a2 and R1∩R2 are re-allocated from a1 to a2 (resulting in an allocation of all R2 resources to a2). Otherwise: (1) if MSA, then all available R2−R1 resources are allocated to a2 and R1∩R2 are re-allocated from a1 to a2; (2) a2 is added to q2.
- If all R2 resources have been allocated to a2, it is started. In addition, if MSA, the release of all R1−R2 resources is requested, else the release of all R1 resources is requested.
- ON release request for R1−R2:
- If q1 is not empty and the resources R1∩R2 required by both A1 and A2 are available, they are allocated and R1−R2 are re-allocated to head( q1); otherwise, R1−R2 are released.
- If the resources R1−R2 have been re-allocated, a new activity of type A1 is started.
- WHEN an activity of type A2 completes:
- There is no state change.
- An immediate release request for R2 is caused/scheduled.
- ON release request for R2:
- If R1∩R2 is nonempty: if q1 is not empty and the resources R1−R2 required by A1, but not yet allocated, are available, they are allocated and R1∩R2 are re-allocated to head( q1); otherwise, R1∩R2 are released. If q2 is not empty, then re-allocate R2−R1 to head( q2); otherwise, R2−R1 are released.
- If R1∩R2 have been re-allocated, a new activity of type A1 is started. If R2−R1 have been re-allocated, a new activity of type A2 is started.
Since the Allocate-Release Modeling Pattern defines a generic algorithm for scheduling resource-constrained activities as well as allocating and releasing resources, its (pseudo-)code does not have to be included in a DPMN Process Diagram, but can be delegated to an OE simulator supporting the resource-dependent scheduling of resource-constrained activities according to this pattern. This approach allows introducing new DPMN modeling elements for expressing the Allocate-Release Modeling Pattern in a concise way, either leaving allocate-release steps completely implicit, as in the DPMN Process Diagram of Figure 7-22, or explicitly expressing them, as in Figure 7-23.
Connecting two Activity rectangles with an RDAS arrow in a DPMN process diagram implies DPMN's standard allocate-release algorithm according to which required resources that have not been allocated before are allocated immediately before an activity requiring them is started and released immediately after this activity is completed if they are not required by a successor activity. More precisely, when an activity of type A is completed, any resource that is not required by a successor activity of type B will be allocated to the next enqueued activity of type A, if there is one, or otherwise released.
Whenever another (non-standard) Allocate-Release logic is needed, it has to be expressed explicitly using conditional event scheduling arrows instead of RDAS arrows.
Example 1: Simplifying the workstation process model
We can now simplify the workstation model using the resource type category for WorkStation in the OE class model and a resource-dependent activity scheduling arrow from the arrival event to the processing activity in the DPMN process model. The resulting class model is shown in Figure 7-26.
The simplification of the process model of Figure 6-3 results in the model of Figure 7-25.

Example 2: Simplifying the medical department process model
We can now simplify the medical department model using the resource type category for Doctor, Room and Nurse in the OEM class model and resource-dependent activity scheduling arrows in the DPMN process model. The resulting class model is shown in Figure 7-26.
The simplification of the rather complex process model of Figure 7-20 by using resource-dependent activity scheduling arrows results in the model of Figure 7-27.

7.4. Organization Modeling Concepts
The activities of a business process are typically performed by human resources holding certain organizational positions that authorize them to play certain organizational roles within an organization or organizational unit. It is, therefore, natural that Activity-Based DES modeling includes organization modeling concepts. In particular, the concept of resource roles and the related concepts of organizational roles and organizational positions are paramount to Activity-Based DES modeling.
Many resource modeling concepts, such as resource roles (including performer roles) and resource pools, can be captured in information models in the form of categorized ("stereotyped") UML class modeling elements such as «rr» for resource role association ends, «pr» for performer role association ends, and «rp» for resource pool association ends, leading to an extension of UML Class Diagrams, called OE Class Diagrams, such as the following one:

This conceptual OE class model describes two activity types, "walks to rooms" and "examinations", each one associated with
- the object type "medical departments", providing the (business) process owner; implying that each specific walk-to-room or examination activity is performed by human resources of, and within a business process owned by, that department;
- a performer object type ("nurses" or "doctors") via a performer role («pr») association end, providing the activity performer (as a special type of resource);
- another resource object type via a resource role («rr») association end, providing another resource of each activity (a "room").
In addition, the model describes three types of resource pools by means of «rp» association ends, such that each resource pool is associated with a process owner maintaining the pool and providing the resources corresponding to one of the three resource roles.
Notice that in a conceptual OE class model, each activity type should have a performer role («pr») association, while in an OE class design model (being part of a simulation design model), it is an option to abstract away from the distinction of performers among the resources of an activity and simply consider all its resources (including its performer) as plain resources. This is common in management science and Operations Research, where the main interest is in obtaining general performance statistics for resources, such as their utilization, no matter if they are active resources (performers) or not.
We show how further organization modeling concepts can be introduced to OEM&S.
Refining Object Types to Resource (Role) Types and Performer (Role) Types
While a resource role of an activity type denotes an association end, corresponding to a reference property of the class implementing the activity type, a resource (or performer) role type denotes an object type that is the range of a resource (or performer) role. For simplicity, we say "resource type" (or "performer type") instead of "resource role type" (or "performer role type").
For all «object type» classes of an OE class model that are the range of a performer role or a resource role, it may be an option to replace their «object type» category with a «performer type» or «resource type» category, as shown for the object types "nurses", "doctors" and "rooms" in the following refined model:

Notice that typically each resource type is the range of one resource role and represents a resource pool for it. A resource type may be the target class of more than one resource role association end and its population may be segmented into several resource pools such that at least one pool is assigned to each resource role.
However, the replacement of the «object type» category of a class with a (performer or resource) role type category is only an option, if all instances of the class are playing that role. In the above example, if there are doctors who do not perform examinations (but only surgical operations), then the object type "doctors" cannot be turned into a performer type "doctors" for examinations, but would have to be partitioned into two subtypes, "surgeons" and "examination doctors", such that the latter would be a performer type for examinations.
In OEM&S, a human performer type is implicitly a subtype of the pre-defined object type Person. This makes it possible that a doctor, as a person that performs examinations, may also be a patient in an examination (of course, with the constraint that a person cannot be the same examination's doctor and patient).
Refining Performer Types to Organizational Positions
An organizational position is defined by a name and a set of human performer types representing the roles of the position holders. For instance, in a medical department, the organizational position Nurse may be defined by the set of performer types Guide and ExaminationAssistant, where a Guide is required for guiding a patient to an examination room and an ExaminationAssistant is required for assisting a doctor in a medical examination.
Computationally, an organizational position is an object type that is co-extensional with all of its performer types, implying that its instances (position holders) are human resources that can be allocated for performing any activity associated with any of these performer types. This implies that any instance (or "holder") of an organizational position is a person and that any organizational position is a subtype of the kind Person.
For instance, the organizational position Nurse is co-extensional with the performer types Guide and ExaminationAssistant, with the meaning that nurses may play the role of guides or the role of examination assistants, and any guide, as well as any examination assistant, is a nurse.
In simple cases, an organizational position is defined by just one performer type for one particular performer role.
In OEM&S, for each organizational position (like Clerk) consisting of the performer roles p1,...,pn, there is a default resource pool, or better: performer pool, (like clerks) that includes all employees holding that position. This pool will be used for allocating the performers of activities with a performer role pi.
These considerations lead to the following refined version of the medical department model shown in the diagram above:

Notice that in this refined model, we have also categorized the object type "patients" as «person role type» and the object type "medical departments" as «organizational unit type». In OEM&S, a person role type, like Patient, is implicitly a subtype of the pre-defined object type Person, allowing a doctor to be a patient. An organizational unit, as an instance of an organizational unit type, may own one or more business processes.
Assigning business process types and business goals to organizational agents
An organizational agent, which is either an organization, an organizational unit or an organizational role player, can own business process types and can have business goals, which allow improving business processes by refactoring business process models, including resource allocation policies, and by changing the populations of resource pools, in such a way that the goals of the process owner (and those of its super-agents) are satisfied.
Consider the following example:
A business company has a Marketing department owning a Lead Generation process, a Business Development unit owning a Lead Qualification process, a Sales department owning a Sales process and a Customer Success department owning a Customer Success process. The company has the overall top-level goals "increase profit", "increase customer satisfaction", and "increase employee motivation".
Without the overall company goals in mind, each organizational unit is prone to optimize their subprocess without keeping an eye on the long-term implications:
- Marketing maximizes lead output and ignores that most leads it generates won’t be qualifiable.
- In its struggle to identify high-quality leads in a mass of low-quality lead data, Business development is overly eager to interpret leads as ‘qualified’, even if it is clear that many leads they forward to Sales can’t be turned into long-term customers.
- Sales tries to close as many deals as possible, without considering churn and missed up-sell opportunities if the product can’t deliver on the promises made.
- Customer success can’t do more than fight the fires of customer dissatisfaction.
This behavior is often encouraged by middle management that sets simple and easily quantifiable short-term performance goals for the team that reports to them, without keeping the big picture in mind.
There are different ways of expressing business goals. In simulation modeling, we need operational forms of business goals, that is, expressions in a formal language. We consider three forms of business goals:
- Definite goals (like "raise the overall revenue by at least 25%") are defined by a logical condition (like relativeRevenueRise >= 0.25) that can be checked by a simulator.
- Variable change goals are defined by a combination of one of the verbs "increase" or "decrease" with the name of a variable (like "profit", "customer satisfaction" or "costs").
- Optimization goals are (more ambitious) special variable change goals defined by a combination of one of the verbs "maximize" or "minimize" with the name of a variable (like "profit", "customer satisfaction" or "costs").
7.5. Resource Modeling
Business process models focus on describing the possible sequences of events and activities, based on conditional and parallel branching. But they may also describe resource roles, which associate resources of a certain type with activities of a certain type.
In the field of Business Process Management (BPM), there is a tendency to consider workflow processes as paradigmatic for business processes. However, workflow processes typically only have (human) performer resources, while business processes in general often have one or more passive resources in addition to a performer. Due to this tendency, BPM research often adopts a simplistic view of business processes.
E.g., in (Pufahl et al. 2021), resource allocation is defined as the “assignment of a process task to the most appropriate resource”, while in general, it’s the other way around: resources are assigned to a task. The authors also point out that the vast majority of BPM research studies on resource allocation make the assumption that a task requires just one resource and a resource cannot be used in more than one task at the same time. As opposed to this simplistic view of business processes in BPM, in DES, tasks can have more than one required resource, and resources may be used in more than one task at the same time.
It is important to distinguish between the passive resources required for performing an activity and the inputs required for performing a processing (or transformation) activity. While the passive resources used in an activity survive the activity, and can be reused in the next one, inputs are either processed, or transformed, into outputs of the activity, and cannot be reused for the next activity. In the literature, this conceptual distinction is often not made. Instead, e.g., in (Russell et al. 2004; Goel and Lin 2021), processing activity inputs are called ‘consumable resources’. However, resources cannot be ‘consumed’, but they can be worn out by activities, such that if their degree of wear falls below a certain threshold, they can no longer be used and are depleted.
For various reasons, resources can go out of order: machines may fail or may have to get scheduled maintenance, nurses or doctors may get sick or may be out-of-duty or off-shift. Consequently, both planned and unexpected resource outages may have to be modeled.
7.5.1. Resource Cardinality Constraints and Multitasking Constraints
Since activities require resources, and resources are allocated to planned activities, it is crucial to understand the relationship between activities and resources. An important part of its meaning are resource cardinality constraints and multitasking constraints.
Business process models do not only describe the possible sequences of events and activities, but they also describe the dependency of activities on resources. For instance, in a BPMN process diagram, a Lane L (such as the doctors lane in the BPMN process diagram below) may represent a resource type such that the diagram specifies for any Activity rectangle A in L (such as examinations) that an activity of type A is performed by a resource of type L.

While using a container shape, such as a BPMN Lane, for assigning elements, such as activities, to the element represented by the container shape (viz, a resource role) is a good way of visually expressing a many-to-one relationship between activity types and resource roles (all activity types within a Lane do have exactly one resource role), it does not allow expressing one-to-many or many-to-many relationships between activity types and resource roles.
Therefore, the BPMN Lane notation can only be used for specifying a performer resource role for activities that do not require resources of other types, and where we have a one-to-one association: (1) a resource can be allocated to at most one activity, and (2) an activity is performed by exactly one resource.
In general, though, the relationships between activities (of some type) and resources (of some type) can be best described by binary relationship types in an information model, such as by binary associations in a UML class diagram with multiplicity expressions at both ends. Figure 7-29 shows two one-to-one associations between the activity type examinations and the object types rooms and doctors associating a room as a (passive) resource and a doctor as a performer resource to an examination activity.

The association end at the side of the object type doctors is categorized as a resource role with the help of UML’s stereotype notation. The multiplicity expression at the resource role end is called resource multiplicity. In our example, the resource multiplicity at the doctors end is ”1” (an abbreviation of "1..1"), which means that exactly one doctor is required for performing an examination, defining a resource cardinality constraint that is a conjunction of a minimum resource cardinality constraint ("at least one") and a maximum resource cardinality constraint ("at most one").
In general, a multiplicity expression defines both a lower bound and an upper bound. When the lower bound of a resource multiplicity is greater than 0, it defines a minimum resource cardinality constraint. When the upper bound of a resource multiplicity is a natural number greater than 0, it defines a maximum resource cardinality constraint. The resource multiplicity 0..* (where * stands for unbounded), which does not define any resource cardinality constraint, is rather unusual since normally all activities require at least one resource (their performer).The multiplicity of the association end at the other side (of the activity type) represents a multitasking constraint, which defines if a resource is exclusively allocated to an activity, or to how many activities a resource can be allocated at the same time. In our example, the multiplicity 0..1 represents a multitasking constraint stating that, at any point in time, a doctor can be associated with, or perform, either no examination or at most one examination.
In an Object-Oriented (OO) programming approach, the computational meaning of a resource role is provided by a corresponding property in the class implementing the activity type. In the above example, the resource role association of "examinations" with "doctors" leads to a property doctor in the class Examination, as shown in Figure 7-30.
When activities admit using more resources than required, this means they can be started as soon as the required number of resources are available, but they can also be started with a greater number of resources, typically implying a faster performance.

While the model shown in Figure 7-29 is an example of a one-to-one association between an activity type and a resource object type, which is the only option in BPMN process models, we consider the cases of one-to-many, many-to-one and many-to-many associations in the following subsections.
One-to-Many Relationships
An example of a one-to-many relationship between activity types and resource object types is the association between ”load truck” activities and ”wheel loader” resources shown in Figure 7-31.

Notice that in this diagram, the «resource role» designation of the association end at the side of “wheel loaders” has been abbreviated by the keyword «rr». Its resource multiplicity of 1..2 specifies a minimum resource cardinality constraint of “at least one” and a maximum resource cardinality constraint of “at most two”, meaning that one wheel loader is required and a second one is admissible. When an activity does not require, but admits of, using more than one resource (of the same type), this typically means that the duration of the activity is the more decreasing the more resources are being used.
The one-to-many resource role association of ”load truck” with ”wheel loaders” leads to a property wheelLoaders in the activity class LoadTruck, as shown in Figure 7-32. Notice that this property has the multiplicity 1..2, which means that it is collection-valued and has either a singleton or a two-element collection value.

When activities admit using more resources than required, this means they can be started as soon as the required number of resources are available, but they can also be started with a greater number of resources, typically implying a shorter duration.
Many-to-One Relationships
An example of a many-to-one relationship between activity types and resource object types is the association between ”examination” activities and ”examination room” resources shown in Figure 7-33.

In this example, examination rooms (as resources) admit of up to three examinations being performed at the same time. Such a multitasking constraint can be implemented with the help of a (multitasking) capacity attribute of the class implementing the resource object type. If such a constraint applies to all instances of a resource object type, capacity would be a class-level (”static”) attribute, which is rendered underlined in a UML class diagram, as shown in the following model:

Alternatively, if different examination rooms have different capacities, then capacity would be an ordinary (instance-level) attribute of the class ExaminationRoom.
Many-to-Many Relationships
Examples of many-to-many relationships between activity types and resource object types are rare and typically involve activities going on with interruptions. An example is the association between ”teaching a course” activities and ”teacher” resources shown in Figure 7-34. In this example, the teaching of a course admits at most two teachers who may be involved in at most 7 course teaching activities at the same time.

7.5.2. Organizational Positions and Resource Pools
Since a business process happens in the context of an organization, it is natural to consider the concept of organizational positions, which has been introduced in Section 7.4.
Resource roles (including performer roles), resource types (including performer types), organizational positions and resource pools are defined in an OE class model. A resource role of an activity type is a special type of property having a resource type as its range.
A performer role of an activity type has a performer type as its range. For instance, in the following OE class model, the (implicitly named) performer role orderTaker of the activity type TakeOrder has the performer type OrderTaker as its range. Likewise the object type PizzaMaker is a performer type. A performer type may be an organizational position. For instance, in the following OE class model, both OrderTaker and PizzaMaker are organizational positions, for which an organization hires a number of human resources, forming corresponding resource pools (called orderTakers and pizzaMakers). These resource pools correspond to the direct populations of the two organizational positions.

An organizational position may subsume more than one performer role. In the model above, the organizational position PizzaMaker is an alternative resource subtype of the organizational position OrderTaker, as indicated by the generalization arrow with the category keyword «ar» (a UML "stereotype").
When a resource pool represents an organizational position charged with playing n performer roles, it is used by all n corresponding activity types.
It is an option that the resources of an alternate resource pool, corresponding to an alternative resource subtype, are associated with a lower proficiency level increasing both the duration of activities and their rework probabilities.
7.5.3. Alternate Resource Pools
Certain activities allow alternative resources, when no standard resources are available. For instance, in a pizza service company, when no order taker is available, and a new order call comes in, an available pizza baker can take the order. Or in a hospital, where nurses guide patients to an examination room, when no nurse is available, a receptionist can guide a patient to an examination room.
The general conceptual pattern is that for certain types of activities A (like GuideToRoom), a resource role r (like guide) may be played not only by instances of its direct resource type R (like Guide), but also by instances of an alternative resource type R' (like ExaminationAssistant) or an organizational position P (like Nurse), if they are a subtypes of R (Guide).
When the resource type R is not abstract, then its instances are the preferred resources of activities of type A, and its (possibly preference-rank-annotated) alternate resource subtypes specify types of alternative resources.
By default, for any non-abstract resource type R and for any organizational position P assigned as the range of a resource role r, an OE simulator can create a resource pool with the same (yet pluralized) name, pooling objects instantiating R or P, and assign it to r as the preferred resource pool.
An alternate resource pool can be defined in an OE class model by means of an alternate resource subtyping arrow (a UML generalization arrow designated with «ar») between the alternative resource type and the resource type concerned as shown in the following diagram, where PizzaMaker is modeled as an alternative resource subtype of OrderTaker:
7.5.4. Task Priorities
Whenever an activity of type A1 ends and there is still another A1 task in the queue, the activity's resources would be re-used for the next A1 task unless there is another task (say, of type A2) with higher priority waiting for one of the resources (r1). In that case, r1 is allocated to that task, and all other resources are allocated to the next A1 task, which still has to wait for r1 becoming available again.
For example, in a pizza service, where incoming orders can be taken by pizza makers, and TakeOrder tasks have a higher priority than MakePizza tasks, when a MakePizza activity performed by a pizza maker in an oven ends while there is still another MakePizza task in the queue and there is also a TakeOrder task in the queue, the pizza maker is allocated to the TakeOrder task and the oven is allocated to the next MakePizza task, which has to wait for a pizza maker becoming available.
Algorithmically: Whenever an activity a1 of type A1 ends, collect all pairs <r, t> such that r is a resource used by a1 and t is the next task of an activity type A from the dependent activity types DAT of pool(r) with the highest priority among all DAT with task priorities higher than A1. For all these pairs <r, t>, allocate r to t. Allocate the remaining resources of a1 to the next A1 task, if there is any, otherwise release them.
7.5.5. Activity Preemption
An ongoing activity may be preempted by a higher-priority task requiring a resource used by the ongoing activity. In such a case, the activity is either aborted or suspended, and the required resource is released from it and allocated to the higher-priority task. A suspended activity may be later resumed when a resource of the required type becomes available again.
7.5.6. Resource Outages
For various reasons, resources can go out of order: machines may fail or may have to get scheduled maintenance, nurses or doctors may get sick or may be out-of-duty or off-shift. Consequently, both planned and unexpected resource outages may have to be modeled.
While human resources being out-of-duty or off-shift can be modeled with the help of service time calendars, scheduled maintenance may be modeled in the form of maintenance activities recurring with a fixed interval. Unexpected resource outages are resource failures.
Modeling Resource Failures
Resource failures can be modeled with the help of two types of events: failure and recovery, and two related random variables: time-to-next-failure and failure time. In this approach, the next resource failure event occurs x time units after a recovery event, where x is obtained by invoking the random variable sampling function timeToNextFailure(). Each failure event triggers a recovery event, which is scheduled with a delay of y time units where y is obtained by invoking the random variable sampling function failureTime().
This simple approach applies both to non-human and human resources.
Further modeling options:
- Allow specifying a time-to-first-failure, in addition to the time-to-next-failure.
- Allow counting only the busy time of a resource, instead of the total time, for determining its next failure time.
Modeling the Repair of Failed Resources
In activity-based simulation, the basic failure modeling approach can be refined by modeling the repair of a failed non-human resource as an activity whose duration is provided by the random variable repair time and which requires a repair person as a resource, such that the total failure time is the sum of the two random variables repair lead time (the time needed for getting a repair person to start the repair) and repair time.
Then, when a failure event occurs, it triggers a repair activity to start with a delay of x time units and a duration of y time units, where x = repairLeadtime() and y = repairTime(). The next failure event is scheduled to occur z time units after a repair end event, where z is obtained by invoking the random variable sampling function timeToNextFailure().
Modeling the Scheduled Maintenance of Resources
Non-human resources, such as machines, may undergo periodic maintenance for preventing them to fail in the near future. This can be modeled by scheduling periodic maintenance activities every x time units where x = maintenanceIntervall(), along with periodic failure events.
When a maintenance activity starts before the next scheduled failure event has occurred, the simulator has to retract this event from the Future Event List for implementing its prevention by the maintenance activity. The next failure event is scheduled to occur x time units after the maintenance end event, where x is obtained by invoking the random variable sampling function timeToNextFailure().
When a resource fails before its next scheduled maintenance has started, the scheduled maintenance is cancelled (the simulator has to retract the scheduled maintenance start event) and, instead, the failure event triggers a repair activity. Only when the repair activity ends, the next maintenance activity is scheduled with a delay of y time units where y is obtained by invoking the random variable sampling function maintenanceTime().
Further modeling options:
- Allow specifying a time-to-first-maintenance, in addition to the maintenance interval time-to-next-maintenance.
- Allow specifying the recurrence of maintenance activities with a schedule instead of a (typically fixed) maintenance interval.
Defining General Elements for Modeling Resource Outages
A simulation framework/language should support resource outage modeling by allowing to define for each (non-human) resource object type the three pairs of (typically random variable) time functions introduced above and summarized in the following class diagram.

These pairs of time functions have to be used incrementally: specifying maintenance time functions requires specifying repair time functions, which, in turn, requires specifying failure time functions.
Resource Outage Modeling in AnyLogic
AnyLogic is a state-of-the-art DES modeling tool/framework. It allows defining recurrent failures (not with follow-up recovery events, but only with follow-up repair activities) and maintenance for each Resource Pool. There is the option to use only the busy time of a resource for computing its next failure time. For repair activities, there is no possibility to distinguish between repair lead time and repair time. For maintenance activities, it can be defined which task priority they have and if they are preemptive or not. Neither for repair nor for maintenance activities, performer resources can be assigned.
Part IV. Processing Activities and Processing Networks
A Processing Activity is a resource-constrained activity that takes one or more objects as inputs and processes them in some way (possibly transforming them). The processed objects have been called "transactions" in GPSS, "entities" in SIMAN/Arena and also "jobs" in the Operations Research literature, while they are called processing objects in DPMN.
Ontologically, there are one or more objects participating in an activity, as shown in the diagram below. Some of them represent resources, while others represent processing objects. For instance, in the information and process models of a medical department shown in Figure 7-6 and Figure 7-9, there are two processing activity types: walks to room and examinations. In walks to room, since nurses are walking patients to examination rooms, nurses and rooms are resources, while patients are processing objects. In examinations, doctors and rooms are resources, while patients are processing objects. If patients would walk to an examination room by themselves (without the help of a nurse), patients would be the performers of walks to a room, and not processing objects, and, consequently, walks to a room would not be processing activities.

Processing activities typically require immobile physical resources, like rooms or workstation machines, which define the inner nodes of a Processing Network (PN). A Processing Object enters such a network via an Arrival event at an Entry Station, is subsequently routed along a chain of Processing Stations where it is subject to Processing Activities, and finally exits the network via a Departure event at an Exit Station.
The nodes of a PN define locations in a network space, which may be based on a two- or three-dimensional Euclidean space. Consequently, OEM-PN models are spatial simulation models, while basic OEM and OEM-A allow to abstract away from space. When processing objects are routed to a follow-up processing activity, they move to the location of the next processing node. The underlying space model allows visualizing a PN simulation in a natural way with processing objects as moving objects.
Each node in a PN model represents both an object and an event type. An Entry Node represents both an Entry Station (e.g., a reception area or an entrance to an inventory) and an arrival event type. A Processing Node represents both a Processing Station (e.g., a workstation or a room) and a processing activity type. An Exit Node represents both an Exit Processing and a departure event type.
A Processing Flow arrow connecting a Processing Node with another Processing Node or with an Exit Node represents both an event flow and an object flow. Thus, the node types and the flow arrows of a PN are high-level modeling concepts that are overloaded with two meanings.
A PN modeling language should have elements for modeling each of the three types of nodes. Consequently, DPMN-AN has to be extended by adding new visual modeling elements for entry, processing and exit nodes, and for connecting them.
In the field of DES, PNs have often been characterized by the narrative of “entities flowing through a system”. In fact, while in basic DPMN and in DPMN-AN, there is only a flow of events, in DPMN-PN this flow of events is over-laid with a flow of (processing) objects.
PNs have been investigated in operations management and the mathematical theory of queuing (Loch 1998, Williams 2016) and have been the application focus of most industrial simulation software products, historically starting with GPSS (Gordon 1961) and SIMAN/Arena (Pegden and Davis 1992). They allow modeling many forms of discrete processing processes as can be found, for instance, in the manufacturing industry and the services industry.
It is remarkable that the PN paradigm has dominated the discrete event simulation market since the 1990’s and still flourishes today, mainly in the manufacturing and services industries, often with object-oriented and “agent-based” extensions. Its dominance has led many simulation experts to view it as a synonym of DES, which is a conceptual flaw because the concept of DES, even if not precisely defined, is clearly more general than the PN paradigm.
The PN paradigm has often been called a “process-oriented” DES approach. But unlike the business process modeling language BPMN, it is not concerned with a general concept of business process models, but rather with the special class of processing process models for discrete processing systems. A processing process includes the simultaneous handling of several “cases” (processing objects) that may compete for resources or have other interdependencies, while a “business process” in Business Process Management has traditionally been considered as a case-based process that is isolated from other cases.
For PN models, a simulator can automatically collect the following statistics, in addition to the resource-constrained activities statistics described in 7. Resource-Constrained Activities:
- The number of processing objects that arrived at, and departed from, the system.
- The number of processing objects in process (that is, either waiting in a queue/buffer or being processed)
- The average time a processing object spends in the system (also called throughput time).
During a simulation run, it must hold that the number of processing objects that arrived at the system is equal to the sum of the number of processing objects in process and the number of processing objects that departed from the system, symbolically:
Chapter 8. Conceptual Modeling of Processing Networks
For accommodating PN modeling, OEM-A is extended by adding pre-defined types for processing objects, entry node objects, arrival events, processing node objects, processing activities, exit objects and departure events, resulting in OEM-PN. These "built-in" types, which are described in Figure 8-1, allow making PN models based on them simply by making a process model (with DPMN) without the need of making an information/class model as its foundation, as shown in Figure 8-2.

An example of a conceptual PN model: Department of Motor Vehicles
As a simple example of a PN simulation model we consider a Department of Motor Vehicles (DMV) with two consecutive service desks: a reception desk and a case handling desk. When a customer arrives at the DMV, she first has to queue up at the reception desk where data for her case is recorded. The customer then goes to the waiting area and waits for being called by the case handling desk where her case will be processed. After completing the case handling, the customer leaves the DMV via the exit.
Customer arrivals are modeled with an «entry node» element (with name “DMV entry”), the two consecutive service desks are modeled with two «processing node» elements, and the departure of customers is modeled with an «exit node» element (with name “DMV exit”).
DPMN is extended by adding the new modeling elements of
- Entry/Processing/Exit Node rectangles representing node objects that take the form of stereotyped UML object rectangles;
- Processing Flow arrows representing the combination of an object flow arrow with an RDAS arrow (pointing to processing nodes), having a special arrow head consisting of a circle and three bars, as shown in Figure 8-2;
- Object-Event Flow arrows, representing the combined object-event flow from processing nodes to exit nodes, as shown in Figure 8-2.

Using both Processing Flow arrows and Event Flow arrows
While a Processing Flow arrow between two nodes implies both a flow of the processing object to the successor node and the resource-dependent scheduling of the next processing activity, an Event Flow arrow from a processing node to an Event circle represents an event flow where a processing activity end event causes/schedules another event, as illustrated in the example of Figure 8-3.

Chapter 9. Processing Network Design Models
For accommodating PN modeling, OEM-A is extended by adding pre-defined types for processing objects, entry node objects, arrival events, processing node objects, processing activities, exit objects and departure events, resulting in OEM-PN. These "built-in" types, as described in Figure 9-1, allow making PN models based on them simply by making a process model with DPMN without the need of making an OEM class model as its foundation, as shown in Figure 9-2.

Notice that the range of the properties arrivalRecurrence, successorNodes and duration of the built-in object types EntryNode and ProcessingNode is Function, which means that the value of such a property for a specific node is a specific function. While the standard UML semantics does not support such an extension of the semantics of properties in the spirit of the Functional Programming paradigm, its implementation in a functional OO programming language like JavaScript, where objects can have instance-level functions/methods, is straightforward.
The property successorNodes allows to express a function that provides, for any given entry or processing node, a (possibly singleton) set of processing nodes or exit nodes. Such a function can express several cases of routing a processing object from a node to one or more successor nodes:
- a fixed unique successor node for modeling a series of processing nodes connected by (possibly conditional) object flow arrows, as in Figure 9-4;
- a conditional unique successor node for modeling an Exclusive (XOR) Gateway leading to one of several possible successor nodes;
- a variable subset of a set of potential successor nodes for modeling an Inclusive (OR) Gateway;
- a fixed set of successor nodes for modeling a Parallel (AND) Gateway;
In a DPMN diagram, the set of successor nodes of a node is defined by Flow Arrows, possibly in combination with Gateways.
PN example 1: a single workstation
Part arrivals are modeled with an «entry node» element (with name “partEntry”), the workstation is modeled with a «processing node» element, and the departure of parts is modeled with an «exit node» element (with name “partExit”).
DPMN is extended by adding the new modeling elements of PN Node rectangles, representing node objects with associated event types, and PN Flow arrows, representing combined object-event flows. PN Node rectangles take the form of stereotyped UML object rectangles, while PN Flow arrows have a special arrow head, as shown in Figure 9-2.

PN example 2: a workstation may have to rework parts
Parts that turn out to be defective after being processed need to be reworked. This can be modeled by adding an attribute percentDefective to the object type Workstation and suitable logic to the Processing activity end event rule such that in percentDefective % of all cases a processed part cannot depart the system (i.e., is not removed from the input buffer), but is being reworked by another Processing activity.

PN example 3: Department of Motor Vehicles
A Department of Motor Vehicles (DMV) has two consecutive service desks: a reception desk and a case handling desk. When a customer arrives at the DMV, she first has to queue up at the reception desk where data for her case is recorded. The customer then goes to the waiting area and waits for being called by the case handling desk where her case will be processed. After completing the case handling, the customer leaves the DMV via the exit.
Customer arrivals are modeled with an «entry node» element (with name “dmvEntry”), the two consecutive service desks are modeled with two «processing node» elements, and the departure of customers is modeled with an «exit node» element (with name “dmvExit”).

Part V. Formal Semantics of OEM
An OE class model is based on a set of underlying data types (such as Integer, String, etc.). Data types, object types, event types and associations are classifiers, which are types. Also, features, such as attributes, are types. Specialization is a relationship between types that is subject to certain constraints (such as the constraint that object types can only specialize other object types). The meta-classes Type, Specialization, Classifier, and Feature, shown in The abstract syntax of the OE Modeling Language based on KerML meta-classes., are defined in the Kernel Modeling Language developed by the Object Management Group as the foundation of SysML v2 and a future version UML.

Chapter 10. The Logic of Object Event Class Models
An OE class model, like the one presented in Figure 3-1, defines (1) a vocabulary consisting of the names of object types, event types, attributes and associations, and (2) a set of integrity constraints, which are logical statements that have to be satisfied by the (Tarski-model-theoretic) interpretations of the model's vocabulary.
The vocabulary of an OE class model corresponds to the vocabulary of a predicate logical language consisting of names of constants, functions and predicates. Object types and event types correspond to unary predicates, while attributes correspond to unary functions (or binary predicates), and associations correspond to n-ary predicates.
10.1. Object Event Class Models
A multiplicity is an expression l..u consisting of a lower bound l being a non-negative integer and an upper bound u being either a positive integer or the special symbol ∗ standing for unbounded such that either u = ∗ or l ≤ u. Whenever the lower bound l of a multiplicity is greater than 0, it defines a minimum cardinality constraint ("there must be at least l values"). Whenever the upper bound u of a multiplicity is not ∗ (unbounded), it defines a maximum cardinality constraint ("there must be at most u values").
An OE class model (based on a finite set of data types DT) is a 10-tuple
⟨ OT, ET, attr, rng, OAss, PAss, ends, mul, muls, sup ⟩
specifying
- a vocabulary ⟨ OT, ET, attr, OAss, PAss ⟩ consisting of finite sets of object and event type names OT and ET, a finite set of composite attribute names of the form T-a where T ∈ OT ∪ ET and a ∈ attr(T), such that T is both the domain and the namespace of a, a finite set of object type association names OAss, and a finite set of participation association names PAss;
- a function attr for assigning a set of local attribute names to an object or event type;
- a function rng for assigning a range (or co-domain) to any attribute T-a with T ∈ OT ∪ ET and a ∈ attr(T);
- a function ends for assigning a tuple of object types to each object type association from OAss, and an ordered pair of an object type and an event type to each participation association from PAss;
- a function mul for assigning multiplicities both to attributes and association ends (mul also expresses history multiplicities for event class association ends of participation associations);
- a function muls for assigning snapshot multiplicities to event class association ends of participation associations;
a function sup for assigning supertypes to types such that
- for all O ∈ OT, sup(O) ⊆ OT,
- for all E ∈ ET, sup(E) ⊆ ET,
- Event ∈ sup*(E), where Event is the predefined top-level event type and sup* is the transitive closure of sup,
- for all T ∈ OT ∪ ET and T' ∈ sup(T), attr(T') ⊆ attr(T);
- for all event types E ∈ ET, the two implicit attributes startTime and occTime are inherited from the predefined event type Event.
If an OE class model has only binary object type associations, it can be reduced to an association-free model as a septuple
⟨ OT, ET, attr, rng, mul, muls, sup ⟩
by expressing/replacing all associations with the help of corresponding reference attributes, the ranges of which are not data types, but entity types.
10.2. Interpretations
An interpretation of an association-free OE class model is a septuple
I = ⟨ T, c, Obj, Evt, types, startT, occT, I ⟩
such that
- T is a linearly ordered set of time instants and c ∈ T is the current time,
- Obj is a finite set of (currently existing) objects, for which it is assumed that they have been existing in the past and will exist in the future (for simplicity, by assuming a constant universe of objects, neither object creation nor object destruction is considered),
- Evt is a finite set of (past or current) events with occt(e) ≤ c for all e ∈ Evt,
- types is a function that assigns one or more object types to each object from Obj and one or more event types to each event from Evt (types assigns an entity its direct types),
- startT and occT are functions that assign a start time t1 and an occurrence time t2 to each event from Evt such that t1 ≤ t2 ≤ c, and
I is an interpretation function for the vocabulary ⟨ OT, ET, attr ⟩ of the class model such that
- I(O) ⊆ Obj for all O ∈ OT.
- I(E) ⊆ Evt for all E ∈ ET and I(Event) = Evt.
An attribute T-a with multiplicity mul(T-a) = ⟨ l, u ⟩ is interpreted as a function from entities to value sets: I(T-a) : I(T) → 2I(R) for all attributes T-a with T ∈ OT ∪ ET, a ∈ attr(T) and R = rng(T-a), such that for any entity e ∈ I(T) and its attribute value set val = I(T-a)(e),
- the cardinality of val is greater than l and smaller than u,
- if the attribute has a snapshot multiplicity muls(T-a) = ⟨ ls, us ⟩, that is, if the attribute represents the event class association end of a participation association, then if ls> 0, the cardinality of the set of current events in the attribute's value set, card = #{ evt ∈ val | occt(evt) = c}, is greater than ls, and if us≠ ∗, then card ≤ us,
- if T ∈ ET, e.occTime = occt(e) and e.duration = e.occTime - e.startTime.
- For any entity type T ∈ OT ∪ ET and any of its supertypes T' ∈ sup(T), I(T) ⊆ I(T').
Together with a variable value assignment α : V → Obj ∪ Evt for a finite set of entity variables V, an interpretation I allows to interpret expressions of the form v.a where v is an entity variable and a is a (local) attribute name:
Iα(v.a) = I(T-a)(e) where e = α(v) and T ∈ types(e) with a ∈ attr(T)
Whenever the range of an attribute T-a is an entity type T', we can interpret expressions of the form v.a1.a2 where a1 ∈ attr(T) and a2 ∈ attr(T'), which are called path expressions, by iterating the attribute function application. While it is obvious how this works for the case of single-valued attributes a1, in the case of multi-valued attributes a1, all resulting value sets are simply merged together. In this way, we can form path expressions of any length greater than zero.
Satisfaction of Logical Formulas
Finally, we can define how an interpretation Iα, together with a variable value assignment α for a set of data and entity variables, satisfies a logical formula F formed with atomic formulas that are connected with the help of the usual logical operators, which is symbolically expressed as Iα ⊨ F. The base case of atomic formulas includes the following two forms:
Classification atoms have the form C(x) where C is a classifier.
Iα ⊨ C(x) iff α(x) ∈ I(C).
Comparison atoms have the form expr1 o expr2 where each exprk is either a data literal (from one of the underlying datatypes), a variable, or a path expression, and o is one of the usual comparison predicates (=, ≠, <, ≤, >, ≥).
Iα ⊨ expr1 o expr2 iff ⟨ Iα(expr1), Iα(expr2) ⟩ ∈ I(o), where I(o) is the binary relation providing the interpretation of the comparison predicate.
Complex logical formulas formed with the logical operators ¬, ∧, ∨, →, ∀, ∃ are satisfied by an interpretation in the usual way.
Entailment
An OE class model CM entails a logical sentence if the sentence is satisfied by all interpretations of the class model:
CM ⊨ F iff I ⊨ F for all interpretations I of CM
10.3. Integrity Constraints

An OE class model, like the one presented in Figure 3-1, defines the following types of (integrity) constraints:
- Range Constraints
require that an attribute must have a value from the value space of the type that has been defined as its range. For instance, a value of the attribute Person::birthDate must be a date. These (implicit) constraints are expressed in a class diagram by specifying a range for all attributes.
- Mandatory Value Constraints
require that an attribute must have a value. These constraints are expressed in a class diagram with the help of an attribute multiplicity with a lower bound greater than 0. The multiplicity expression is enclosed in brackets and appended to the attribute name. For instance, in the class diagram to the right, an instance of Person must have a name and a birthDate, but need not have a biography. Notice that the default multiplicity of an attribute is [1], implying that it is mandatory and single-valued.
- Cardinality Constraints
apply to multi-valued attributes, only, and require that the cardinality of a multi-valued attribute's value set is not less than a given minimum cardinality or not greater than a given maximum cardinality, as expressed by the attribute's multiplicity.
In addition to these types of attribute constraints, an OE class model may specify two further, more general, types of constraints:
- a set of classifier invariants CInvar, which are ordered pairs of a classifier C and a logical formula, or Boolean expression, F(x) with one free variable x stating that F(i) holds for all i from the extent of C;
- a set of global invariants GInvar, which are logical sentences, or Boolean expressions without free variables.
In a class diagram, classifier invariants are expressed within a constraint rectangle that is attached to a classifier with the help of a dashed line. Global invariants can be expressed within a constraint rectangle in a corner of the diagram.
Interpretations of an OE class model are required to satisfy all of its invariants:
- I ⊨ ∀x: C(x) → F(x) for all classifier invariants ⟨C, F(x)⟩ ∈ CInvar.
- I ⊨ F for all F ∈ GInvar.
There are several types of very common classifier invariants that can be expressed in a class diagram in the simplified way of an attribute annotation in curly braces appended to the attribute declaration:
- Uniqueness Constraints (also called 'Key Constraints')
are expressed with the attribute annotation keyword "key" and require that the value of an attribute a is unique among all instances of its domain: F(x) ≡ ∀y: C(y) → x.a ≠ y.a.
- Interval Constraints
are expressed with the attribute annotation keywords "min" and "max" and require that the value of a numeric attribute a must be in a specific interval [min,max]: F(x) ≡ min ≤ x.a ∧ x.a ≤ max.
- Pattern Constraints
are expressed with the attribute annotation keyword "pattern" and require that a string attribute's value must match a certain pattern defined by a regular expression.
The attribute annotation keyword "id" implies that the attribute is unique and mandatory, and that its values e.a are used as standard identifiers for the entities e.
Examples of global invariants are the following:
Each Departure event must be preceded by a corresponding Arrival event:
∀x [ Departure(x) → ∃y [ Arrival(y) ∧ y.libraryUser = x.libraryUser ∧ y.occTime < x.occTime ∧ ¬∃z [ Departure(z) ∧ z.libraryUser = x.libraryUser ∧ y.occTime < z.occTime ∧ z.occTime < x.occTime ]]]
- For each book copy involved in a BookTakeBack activity there must be a corresponding preceding BookLending activity involving that book copy.
10.4. An Interpretation in the Form of Tables
An interpretation of an OE class model can be expressed with a suitable set of object tables and event tables, which implicitly define (1) a (Herbrand) universe of discourse, (2) the types of individual entities, (3) the start time and an occurrence time of each event, (4) the interpretations of entity types and their attributes.
An example of an interpretation of (a slightly simplified version of) the model presented in Figure 3-1 consists of the following tables:
| persons | |
|---|---|
| id | name |
| 1049 | Tom Banks |
| 1083 | Mary Swift |
| 1102 | Liza Miller |
| 1157 | Su Kang |
| library_users | |
|---|---|
| id | address |
| 1049 | 738 Austin Blv, Manchaca, TX 78652 |
| 1102 | 29 Hank St, Austin, TX 73301 |
| 1157 | 114 Feritti Dr, Austin, TX 78734 |
| books | |
|---|---|
| isbn | title |
| 006251587X | Weaving the Web |
| 0465026567 | Gödel, Escher, Bach |
| 0465030793 | I Am A Strange Loop |
| book_copies | ||
|---|---|---|
| id | isbn | status |
| 2194 | 006251587X | LENDED |
| 2195 | 006251587X | AVAILABLE |
| 2196 | 006251587X | AVAILABLE |
| 1843 | 0465026567 | AVAILABLE |
| 1844 | 0465026567 | LENDED |
| 1172 | 0465030793 | LENDED |
| arrivals | |
|---|---|
| occTime | libraryUser |
| 20240705T09:03 | 1102 |
| 20240705T10:42 | 1157 |
| 20240705T13:29 | 1157 |
| 20240706T09:01 | 1049 |
| 20240706T09:37 | 1102 |
| departures | |
|---|---|
| occTime | libraryUser |
| 20240705T11:17 | 1157 |
| 20240705T12:36 | 1102 |
| 20240705T15:55 | 1157 |
| 20240706T09:58 | 1049 |
| 20240706T10:41 | 1102 |
| book_lendings | |||
|---|---|---|---|
| startTime | occTime | libraryUser | bookCopies |
| 20240705T09:14 | 20240705T09:17 | 1102 | 2195 |
| 20240705T13:46 | 20240705T13:53 | 1157 | 1844, 2194 |
| 20240706T09:08 | 20240706T09:12 | 1049 | 1172 |
| book_take_backs | |||
|---|---|---|---|
| startTime | occTime | libraryUser | bookCopies |
| 20240706T09:42 | 20240706T09:44 | 1102 | 2195, 1843 |
| 20240706T09:33 | 20240706T09:39 | 1049 | 2195 |
An interpretation I = ⟨ T, c, Obj, Evt, types, startT, occT, I ⟩ of a class model ⟨ OT, ET, attr, rng, mul, muls, sup ⟩ can be defined in the form
I = ⟨ T, c, Obj, Evt, ObjTbls, EvtTbls ⟩
where the interpretation function I is defined implicitly by the two sets ObjTbls = {objects1, objects2, …} and EvtTbls = {events1, events2, …} such that
each object type O1 ∈ OT is implicitly mapped to a corresponding object table objects1 ∈ ObjTbls (via a name correspondence) with columns corresponding to the attributes of O1 by having the same names and satisfying their range constraints in the sense that for all rows r ∈ objects1 and all attributes a ∈ attr(O1),
- if the range of a is a data type D = rng(a), then r[a] ∈ Lit(D), where r[a] denotes the data literal contained in the objects1 table cell determined by row r and column a, and Lit(D) denotes the set of data literals associated with D;
- if the range of a is an entity type T = rng(a) with a corresponding entity table tbl, then the corresponding table column is a foreign key column, that is, r[a] ∈ T[a] where T[a] denotes
- for each event type E1 ∈ ET, there is a corresponding event table I(E1) = events1 ∈ EvtTbls having the two special columns startTime and occTime with data literals corresponding to values from the temporal domain T, and all other columns corresponding to the attributes of E1 by the same names and by satisfying their range constraints as for object types;
- Obj is a finite set of (currently existing) objects, for which it is assumed that they have been existing in the past and will exist in the future (for simplicity, by assuming a constant universe of objects, neither object creation nor object destruction is considered),
- Evt is a finite set of (past or current) events with occt(e) ≤ c for all e ∈ Evt,
- types is a function that assigns one or more object types to each object from Obj and one or more event types to each event from Evt (types assigns an entity its direct types),
- startT and occT are functions that assign a start time t1 and an occurrence time t2 to each event from Evt such that t1 ≤ t2 ≤ c, and
I is an interpretation function for the vocabulary ⟨ OT, ET, attr ⟩ of the class model such that
- I(O) ⊆ Obj for all O ∈ OT.
- I(E) ⊆ Evt for all E ∈ ET and I(Event) = Evt.
An attribute T-a with multiplicity mul(T-a) = ⟨ l, u ⟩ is interpreted as a function from entities to value sets: I(T-a) : I(T) → 2I(R) for all attributes T-a with T ∈ OT ∪ ET, a ∈ attr(T) and R = rng(T-a), such that for any entity e ∈ I(T) and its attribute value set val = I(T-a)(e),
- the cardinality of val is greater than l and smaller than u,
- if the attribute has a snapshot multiplicity muls(T-a) = ⟨ ls, us ⟩, that is, if the attribute represents the event class association end of a participation association, then if ls> 0, the cardinality of the set of current events in the attribute's value set, card = #{ evt ∈ val | occt(evt) = c}, is greater than ls, and if us≠ ∗, then card ≤ us,
- if T ∈ ET, e.occTime = occt(e) and e.duration = e.occTime - e.startTime.
- For any entity type T ∈ OT ∪ ET and any of its supertypes T' ∈ sup(T), I(T) ⊆ I(T').
These tables implicitly define
- a Herbrand universe consisting of the two sets Obj = { p(1049), p(1083), …, lu(1049), lu(1102), …, b(006251587X), b(0465026567), …, bc(2194), bc(2195), …} and Evt = { a(20240705T09:03,1102), a(20240705T10:42,1157), …, d(20240705T11:17,1157), …, bl(20240705T09:17, 1102, 2195), …, btb(20240706T09:44, 1102, {2195,1843}), …};
- the types of individual entities, e.g., types( lu(1049)) = { LibraryUser, Person);
- the start time and occurrence time of each event with the help of the corresponding event table columns;
- the interpretation of entity types: e.g., I( LibraryUser) = { lu(1049), lu(1102), lu(1157)};
- the interpretation of attributes: e.g., I( Person-name) = { 1049: 'Tom Banks', 1083: 'Mary Swift', 1102: 'Liza Miller', 1157: 'Su Kang'}.
Chapter 11. Event Graphs
Formally, an EG is defined on the basis of a set of event types ET and a set of state variables V as a directed graph ⟨ N, D ⟩ with nodes N and directed edges D ⊆ N ⨉ N , such that
each node n ∈ N is associated with
- an event type E ∈ ET,
- an event variable e representing an event of type E,
- a (possibly empty) set of variable value assignments of the form v := expr with v ∈ V and an expression expr formed with the help of the event variable e and variables from V, defining an on-event state transition function;
- each directed edge ⟨ n1, n2 ⟩ ∈ D may be associated with
- a numeric delay expression δ possibly expressed with the help of the event variable e and variables from V,
- a condition (or Boolean expression) C expressed with the help of the event variable e and variables from V.
11.1. The Operational Semantics of Event Graphs
We illustrate the formal semantics of ES with the help of an example. We model a system of one or more service desks, each of them having its own queue, as a discrete event system characterized by the following narrative:
- Customers arrive at a service desk at random times.
- If there is no other customer in front of them, and the service desk is available, they are served immediately, otherwise they have to queue up in a waiting line.
- The duration of services varies, depending on the individual case.
- When a service is completed, the customer departs and the next customer is served, if there is still any customer in the queue.
The base concepts of ES are:
- state variables for describing the state of a system,
- event types,
- event expressions,
- event routines,
- future events lists (FEL).
A state variable is declared with a name and a range, which is a datatype defining its possible values.
An event type is defined in the form of a class: with a name, a set of property declarations and a set of method definitions, which together define the signature of the event type.
An event expression is a term E(x)@t where
- E is an event type,
- t is a parameter for the occurrence time of events,
- x is a (possibly empty) list of event parameters x1, x2, …, xn according to the signature of the event type E.
For instance, Arrival@t is an event expression for describing Arrival events where the signature of the event type Arrival is empty, so there are no event parameters, and the parameter t denotes the arrival time (more precisely, the occurrence time of the Arrival event). An individual event of type E is a ground event expression, e = E(v)@i, where the event parameter list x and the occurrence time parameter t have been instantiated with a corresponding value list v and a specific time instant i. For instance, Arrival@1 is a ground event expression representing an individual Arrival event.
An event routine is a procedure that essentially computes state changes and follow-up events, possibly based on conditions on the current state. In practice, state changes are often directly performed by immediately updating the state variables concerned, and follow-up events are immediately scheduled by adding them to the FEL. However, for defining the formal semantics of ES, we assume that an event routine is a pure function that computes state changes and follow-up events, but does not apply them, as in the rules described in Table 11-1.Event rule name | ON (event expression) | DO (event routine) |
rArr | Arrival @ t | E’ := { Arrival @ (t + recurrence()) } |
rDep | Departure @ t | E’ := {} |
An event rule associates an event expression with an event routine F:
ON E(x)@t DO F( t, x),
where the event expression E(x)@t specifies the type E of events that trigger the rule, and F( t, x) is a function call expression for computing a set of state changes and a set of follow-up events, based on the event parameter values x, the event's occurrence time t and the current system state, which is accessed in the event routine F for testing conditions expressed in terms of state variables.
A Future Events List (FEL) is a set of ground event expressions partially ordered by their occurrence times, which represent future time instants either from a discrete or a continuous model of time. The partial order implies the possibility of simultaneous events, as in the example { Departure@4, Arrival@4 }.
ES Models
An ES model is a triple ⟨ SV, ET, R ⟩ where
- SV is a set of state variable declarations defining the structure of possible system states,
- ET is a set of event type definitions,
- R is a set of event rules expressed in terms of SV and ET.
We show how to express the example model of a simple service desk system as an ES model. The set of state variables is a singleton:
SV = { queueLength: NonNegativeInteger}
There are two event types, both having an empty signature:
ET = { Arrival(), Departure()}
And there are two event rules:
R = { rArr, rDep}
which are defined as in Table 1 above.
Such a model, together with an initial state (specifying initial values for state variables and initial events), defines an ES system, which is a transition system where
- system states are defined by value assignments for the state variables,
- transitions are provided by event occurrences triggering event rules that change the simulation state through changing the system state (by changing the values of affected state variables) and the FEL (by adding follow-up events).
Whenever the transitions of an ES system involve computations based on random numbers (if the simulation model contains random variables), the transition system defined is non-deterministic.
For instance, assuming that the initial system state is S0 = {queueLength: 0}, and there is an initial event {Arrival@1}, then, as a consequence of applying rArr, there is a system state change {queueLength := 1} and, assuming a random service time of 2 time units (as a sample from the underlying probability distribution function), a follow-up event Departure@3, which has to be scheduled along with the next Arrival event, say Arrival@3 (with a random inter-arrival time of 2), because Arrival is an exogenous event type (with a random recurrence). Consequently, the next system state is S1 = {queueLength: 1}.
We need to distinguish between the system state, like S0 = {queueLength: 0}, which is the state of the simulated system, and the simulation state, which adds the FEL to the system state, like
S0 = ⟨ {queueLength: 0}, {Arrival@1} ⟩
S1 = ⟨ {queueLength: 1}, {Arrival@2, Departure@3} ⟩
Doing one more step, the next transition is given by the next event Arrival@2 again triggering rArr, which leads to
S2 = ⟨ {queueLength: 2}, {Departure@3, Arrival@4} ⟩
In this way, we get a succession of states S0 → S1 → S2 → … as a history of the transition system defined by the ES model.
Event Rules as Functions
An event rule r = ON E(x)@t DO F( t, x) can be considered as a 2-step function that, in the first step, maps an event e = E(v)@i to a parameter-free state change function re = F( i, v), which maps a system state to a pair ⟨ Δ, E' ⟩ of system state changes Δ and follow-up events E'. When the parameters t and x of F( t, x) are replaced by the values i and v provided by a ground event expression E(v)@i, we also simply write Fi,v instead of F( i, v) for the resulting parameter-free state change function.
We say that an event rule r is triggered by an event e when the event’s type is the same as the rule’s triggering event type. When r is triggered by e, we can form the state change function re = Fi,v and apply it to a system state S by mapping it to a set of system state changes Δ and a set of follow-up events E':
re(S) = Fi,v(S) = ⟨ Δ, E' ⟩
We can illustrate this with the help of our running example. Consider the rule rArr defined in Table 1 above triggered by the event Arrival@1 in state S0 = {queueLength: 0}. The resulting state change function F1 defined by the corresponding event routine from Table 1 maps S0 to the set of state changes Δ = { INCREMENT queueLength} and the set of follow-up events E' = {Departure@3}. We show how the pair ⟨ Δ, E' ⟩ amounts to a transition of the simulation state in the next section.
In ES, a system state change is an update of one or more state variables. Such an update is specified in the form of an assignment where the right-hand side is an expression that may involve state variables. For instance, the state change INCREMENT queueLength is equivalent to the assignment queueLength := queueLength + 1.
In general, there may be situations, where we have several concurrent events, that is, there may be two or more events occurring at the same (next-event) time. Therefore, we need to explain how to apply a set of rules RE triggered by a set of events E, even if both sets are singletons in many cases.
The rule set R of an ES model can also be considered as a 2-step function that, in the first step, maps a set of events E to a state change function RE, which maps a system state to a pair ⟨ Δ, E' ⟩ of state changes Δ and follow-up events E'.
For a given set of events E and a rule set R, we can form the set of state change functions obtained from rules triggered by events from E:
RE = { re : r ∈ R & e ∈ E & e triggers r}
Notice that the elements C of RE are parameter-free state change functions, which can be applied as a block, in parallel, to a system state S:
RE(S) = ⟨ Δ, E' ⟩
with
Δ = ⋃ { ΔC : C ∈ RE & C(S) = ⟨ ΔC, E'C ⟩ }
E' = ⋃ { E'C : C ∈ RE & C(S) = ⟨ ΔC, E'C ⟩ }
Notice that when forming the union of all state changes brought about by applying rules from RE, and likewise when forming the union of all follow-up events created by applying rules from RE, the order of rule applications does not matter because they do not affect the applicability of each other, so any selection function for choosing rules from RE and applying them sequentially will do, and they could also be applied simultaneously if such a parallel computation is supported.
However, computing a set of state changes Δ raises the question if this set is, in some sense, consistent. A simple, but too restrictive, notion of consistent state changes would require that if Δ contains two or more updates of the same state variable, all of them must be equivalent (effectively assigning the same value). A more liberal notion just requires that if Δ contains two or more updates of the same state variable, their collective application must result in the same value for it, no matter in which order they are applied.
If Δ contains inconsistent updates for a state variable, this may be a bug or a feature of the simulation model. If it is not a bug, a conflict resolution policy is needed. The simplest policy is ignoring, or discarding, all inconsistent updates. Another common conflict resolution policy is based on assigning priorities to event rules.
Consider again our running example with a system state S = {queueLength: 1} and the set of next events N = {Arrival@4, Departure@4}. Then, RN consists of the two parameter-free change functions:
- F1: function () {Δ := { INCREMENT queueLength}; IF queueLength = 0 THEN
E' := { Departure @ (4 + serviceDuration())}; RETURN ⟨ Δ, E' ⟩ } - F2: function () {Δ := { DECREMENT queueLength}; IF queueLength > 1 THEN
E' := { Departure @ (4 + serviceDuration())}; RETURN ⟨ Δ, E' ⟩}
No matter in which order we apply F1 and F2, forming the union of their state changes always results in Δ = {}, because the incrementation and decrementation of the variable queueLength neutralize each other, and forming the union of their follow-up events always results in E' = { Departure@(4+d)} where d is the random value returned by the serviceDuration function.
An Event Rule Set as a Simulation State Transition Function
We show that the event rule set R of an ES model ⟨ SV, ET, R ⟩ defines a transition function that maps a simulation state ⟨ S, FEL ⟩ to a successor state ⟨ S', FEL' ⟩ in 3 steps:
- R maps the set of next events N extracted from the FEL to a set RN of state change functions of rules triggered by one of the next events from N.
- RN maps the current system state S to a set of state changes Δ and a set of follow-up events E'.
- The pair ⟨ Δ, E' ⟩ amounts to a transition of the current simulation state ⟨ S, FEL ⟩ by applying the updates from Δ to S yielding S’ and by removing N from FEL and adding E'.
We have already explained how to obtain RN from R and how to apply RN to S for getting ⟨ Δ, E' ⟩ in the previous subsection, so we only need to provide more explanation for the last step: processing ⟨ Δ, E' ⟩ for obtaining the next simulation state ⟨ S', FEL' ⟩.
Let Upd denote an update operation that takes a system state S and a set of state changes Δ, and returns an updated system state Upd( S, Δ). When the system state consists of state variables, the update operation simply performs variable value assignments. Using this operation, we can define the third step of the simulation state transition function with two sub-steps in the following way:
- S' = Upd( S, Δ)
- FEL' = FEL − N ⋃ E'
This completes our definition of how the event rule set R of an ES model works as a transition function that computes the successor state of a simulation state:
R(⟨ S, FEL ⟩) = ⟨ S', FEL' ⟩
such that for a given initial simulation state S0 = ⟨ S0, FEL0 ⟩, we obtain a succession of states
S0 → S1 → S2 → …
by iteratively applying R:
Si+1 = R( Si)
Consider again our running example. In simple cases we do not have more than one next event, so RN is a singleton and we do not have to apply more than one rule at a time. For instance, when
S1 = ⟨{ queueLength: 1}, {Arrival@2, Departure@3}⟩
There is only one next event: Arrival@2, so we do not have to form a set of applicable rules, but can immediately apply the rule triggered by Arrival@2 for obtaining a set of system state changes and a set of follow-up events:
rArr ( S1) = ⟨{ queueLength := 2}, {Arrival@4}⟩
Now consider a simulation state where we have more than one next event, like the following one:
S3 = ⟨{ queueLength: 1}, {Arrival@4, Departure@4}⟩
We obtain
R( S3) = ⟨{ queueLength: 1}, {Arrival@5, Departure@6}⟩
assuming a random inter-arrival time sample of 1 and a random service duration sample of 2.
Chapter 12. Object Event Graphs
Formally, an OEG is defined on the basis of a set of object types OT and a set of event types ET as a directed graph ⟨ N, D ⟩ with nodes N and directed edges D ⊆ N ⨉ N , such that
each node n ∈ N is associated with
- an event type E ∈ ET with event participation roles PE,
- an event variable e representing an event of type E,
- a (possibly empty) set of auxiliary (shortcut) object variables o defined with the help of event participation roles p ∈ PE by setting o := e.p,
- a (possibly empty) set of definitions of on-event object state transition functions { fp | p ∈ PE };
- each directed edge ⟨ n1, n2 ⟩ ∈ D may be associated with
- a numeric delay expression δ possibly expressed with the help of the variables associated with n1,
- a condition (or Boolean expression) C expressed with the help of the variables associated with n1.
The formal (transition system) semantics of OEGs, based on the semantics of event rules as transition functions, has been presented in (Wagner 2017). It can be shown that the OEG diagram language is a conservative extension of the Event Graph diagram language by means of a homomorphic embedding of Event Graphs in OEGs.
12.1. The Operational Semantics of Object Event Graphs
The operational semantics of Object Event Models proposed in (Wagner 2017) can be summarized as follows.
Both object types and event types are defined in the form of classes: with a name, a set of properties and a set of operations, which together define their signature. A property is essentially defined by a name and a range, which is either a datatype (like Integer or String) or an object type.A set of object types OT defines a predicate-logical signature as the basis of a logical expression language LOT: each object type defines a unary predicate, and its properties define binary predicates. A state change language COT based on OT defines state change statements expressed with the help of the object type names and property names defined by OT. In the simplest case, state change statements are property value assignments like o.p1 := 4 or o.p1 := o.p2 where o is an object variable and p1, p2 are property names.
A set of objects O = {o1, o2, ...on} where each of them has a state in the form of a set of slots (property-value pairs) represents a system state, that is a state of the real-world system being modeled and simulated. A system state O can be updated by a set of state changes (or, more precisely, state change statements) Δ ⊆ COT with the help of an update operation Upd. For instance, for a system state O1 = {o1} with o1 = { p1: 2, p2: 5} and a set of state changes Δ1 = { o1.p1 := o1.p2 } we obtain
An event expression is a term E(x)@t where
- E is an event type,
- x is a (possibly empty) list of event parameters x1, x2, …, xn according to the signature of the event type E,
- t is a parameter for the occurrence time of events.
For instance, PartArrival(ws)@t is an event expression for describing part arrival events where the event parameter ws is of type WorkStation, and t denotes the arrival time. An individual event of type E is a ground event expression, e = E(v)@i, where the event parameter list x and the occurrence time parameter t have been instantiated with a corresponding value list v and a specific time instant i. For instance, PartArrival(ws1)@1 is a ground event expression representing an individual PartArrival event occurring at workstation ws1 at time 1.
A Future Events List (FEL) is a set of ground event expressions partially ordered by their occurrence times, which represent future time instants either from a discrete or a continuous model of time. The partial order implies the possibility of simultaneous events, as in the example {ProcessingEnd(ws1)@4, PartArrival(ws1)@4}.An event routine is a procedure that essentially computes state changes and follow-up events, possibly based on conditions on the current state. In practice, state changes are often directly performed by immediately updating the objects concerned, and follow-up events are immediately scheduled by adding them to the FEL. For the OES formalism, we assume that an event routine is a pure function that computes state changes and follow-up events, but does not apply them, as illustrated by the examples in the following table.
Event rule name / rule variables | ON (event expression) | DO (event routine) |
rPA a: PartArrival | PartArrival(ws) @ t | Δ := { ws.waitingParts.push( a.part)} IF ws.status = AVAILABLE RETURN ⟨ Δ, FE ⟩ |
rPS ps: ProcessingStartws: WorkStation ws := ps.workStation | ProcessingStart(ws) @ t | Δ := { ws.status := BUSY} FE := {ProcessingEnd(ws)@t + ProcessingStart.processingTime()} RETURN ⟨ Δ, FE ⟩ |
rPE pe: ProcessingEndws: WorkStation ws := pe.workStation | ProcessingEnd(ws) @ t | Δ := { ws.waitingParts.pop()} IF ws.waitingParts.length > 0 RETURN ⟨ Δ, FE ⟩ |
An event rule associates an event expression with an event routine F:
where the event expression E(x)@t specifies the type E of events that trigger the rule, and F( t, x) is a function call expression for computing a set of state changes and a set of follow-up events, based on the event parameter values x, the event's occurrence time t and the current system state, which is accessed in the event routine F for testing conditions expressed in terms of state variables.
An OE model based on a state change language COT and a corresponding update operation Upd is a triple ⟨OT, ET, R⟩, consisting of a set of object types OT, event types ET and event rules R.
An OE simulation (system) state based on an OE model ⟨OT, ET, R⟩ is a triple S = ⟨t, O, E⟩ with t being the current simulation time, O being a system state (a set of objects instantiating types from OT), and E being a set of imminent events to occur at times greater than t (and instantiating types from ET), also called Future Event List (FEL).An event rule r = ON E(x)@t DO F( t, x) can be considered as a 2-step function that, in the first step, maps an event e = E(v)@i to a parameter-free state change function re = F( i, v), which maps a system state O to a pair ⟨ Δ, FE ⟩ of system state changes Δ ⊆ COT and follow-up events FE. When the parameters t and x of F( t, x) are replaced by the values i and v provided by a ground event expression E(v)@i, we also simply write Fi,v instead of F( i, v) for the resulting parameter-free state change function.
We say that an event rule r is triggered by an event e when the event's type is the same as the rule's event type. When r is triggered by e, we can form the state change function re = Fi,v and apply it to a system state O by mapping it to a set of state changes and a set of follow-up events:
We can illustrate this with the help of our workstation example. Consider the rule rPA defined in the table above triggered by the event PartArrival(ws1)@1 in state O0 = {ws1.status: AVAILABLE, ws1.waitingParts: []}. We obtain
with Δ1 = { ws1.waitingParts.push( a.part)} and FE1 = {ProcessingStart@2}.
An OE model defines a state transition system where
A state is a simulation state S = ⟨t, O, E⟩.
A transition of a simulation state S consists of
advancing t to the occurrence time t' of the next events NE ⊆ E, which is the set of all imminent events with minimal occurrence time;
processing all next events e ∈ NE by applying the event rules r ∈ R triggered by them to the current system state O according to
re( O ) = ⟨ Δe , FEe ⟩resulting in a set of state changes Δ = ∪ {Δe | e ∈ NE } and a set of follow-up events FE = ∪ {FEe | e ∈ NE }.
such that the resulting successor simulation state is S' = ⟨ t', O', E' ⟩ with O' = Upd( O, Δ) and E' = E − NE ∪ FE.
Notice that the OES formalism first collects all state changes brought about by all the simultaneous next events (from the set NE) of a simulation step before applying them. This prevents the state changes brought about by one event from NE to affect the application of event rules for other events from NE, thus avoiding the problem of non-determinism through the potential non-confluence (or non-serializability) of parallel events.
OE simulators are computer programs that implement the OES formalism. Typically, for performance reasons, discrete event simulators do not first collect all state changes brought about by all the simultaneous next events (the set NE) of a simulation step before applying them, but rather apply them immediately in each triggered event routine. However, this approach takes the risk of an unreliable semantics of certain simulation models in favor of performance.
Chapter 13. Activity Networks
Formally, an AN is defined on the basis of a set of object types OT, a set of event types ET and a set of activity types AT as a directed graph ⟨ N, D ⟩ with two types of nodes N = EN ⋃ AN, event nodes and activity nodes, and two types of directed edges D = ED ⋃ AD, event scheduling edges and resource-dependent activity scheduling edges, with ED ⊆ N ⨉ EN and AD ⊆ N ⨉ AN, such that
each event node n ∈ EN is associated with
- an event type E ∈ ET with event participation roles PE,
- an event variable e representing an event of type E,
- a (possibly empty) set of auxiliary (shortcut) object variables o defined with the help of event participation roles p ∈ PE by setting o := e.p,
- a (possibly empty) set of definitions of on-event object state transition functions { fp | p ∈ PE };
each activity node n ∈ AN is associated with
- an activity type A ∈ AT with activity participation roles PA,
- an activity variable a representing an activity of type A,
- a (possibly empty) set of auxiliary (shortcut) object variables o defined with the help of activity participation roles p ∈ PA by setting o := a.p,
- a (possibly empty) set of definitions of on-activity-start object state transition functions { sfp | p ∈ PE };
- a (possibly empty) set of definitions of on-activity-end object state transition functions { efp | p ∈ PE };
- each event scheduling edge ⟨ n1, n2 ⟩ ∈ ED may be associated with
- a numeric delay expression δ possibly expressed with the help of the variables associated with n1,
- a condition (or Boolean expression) C expressed with the help of the variables associated with n1.
Part VI. Agent-Based Modeling and Simulation
The term "agent-based modeling" is an umbrella term that subsumes many different approaches to simulation, typically focused on modeling (collections of) entities/objects/individuals/"agents" and their interactions with each other and with their environment. In any case, since the interactions of agents are based on discrete perception and action events, it is natural to define an agent-based modeling and simulation approach as an extension of a DES approach, such that it is an option to use the concept of agents along with the more basic concepts of objects and events. Along these lines, OEM&S can be extended by adding the concept of agents, together with concepts of perception and action events as well as communication, resulting in Agent/Object Event Modeling and Simulation (A/OEM&S).
In academic research, the term "agent-based" M&S is used ambiguously both for individual-based and cognitive agent M&S. The former, which is also called "microscopic" simulation (or micro-simulation), is focused on modeling (collections of) individuals and their interactions with each other and with their environment for modeling complex systems, whereas the latter is more concerned with modeling the cognitive state and cognitive operations of an agent.
Consequently, it seems natural to distinguish between a weak concept of agents, which we call basic agents, where agents are entities that interact with their environment and with each other, and a strong concept, called cognitive agents, that is based on modeling the cognitive (or mental) state and operations of agents.
The cognitive state of basic agents has only one component: their information state containing propositional information about their environment and about themselves resulting both from perception and from communication. A propositional information item of an information state can be expressed in the form of a triple statement (or, simply, triple), which is an atomic predicate logic sentence that consists of (1) an object name, (2) a property name, and (3) a property value. Such an information item can be viewed as a belief of an agent, or as a knowledge item (where knowledge means correct information or true belief).
Beliefs represent the typically partial and sometimes incorrect subjective information of agents about their environment and about themselves. They are the most basic component of the cognitive state of an agent. The simplest model of a cognitive state only consists of beliefs, while more advanced models may also include commitments, goals, intentions, emotions, etc.
Many agent-based (in particular, individual-based) M&S approaches do not attempt to support the incompleteness of beliefs/information or the possibility of incorrect beliefs/information. They make the (tacit) assumption that agents have perfect information and focus on modeling interactive behavior: (1) the interaction of an agent with its inanimate environment via a perception-action cycle, and (2) the communication between agents.
A general model of the interactive behavior of agents depends, at least, on their information state, which is
- queried for decision making, and from which information items are retrieved for informing other agents;
- updated when new information is obtained by means of perception or communication.
In the general case of a cognitive agent with possibly false beliefs, its belief state (or subjective information state) has to be represented as a kind of restricted and modified duplicate of the objective information state managed by the simulator, requiring a more complex simulator architecture. Within such an architecture, the information state of a perfect information agent has to be short-circuited with the objective information state managed by the simulator.
Chapter 14. Basic Agents with Perfect Information
Basic agents are objects that (1) have an information state, (2) may have perceptions of their environment affecting their information state, and (3) may communicate with each other and, as a consequence, change their information state. We define perfect information agents as basic agents that
- have complete and correct information about all objects they know;
- are sincere: they do not provide intentionally incorrect information in their communications with other agents (that is, they do not lie).
Condition 1 does not hold for physical agents in the real-world, such as humans, animals or robots. Rather it's a simplifying assumption that we may want to make in a simulation model abstracting away from the limitations of real-world agents. Condition 2 typically holds for robots (and other artifact agents), but not for humans.
In A/OEM&S, agents are, by default, perfect information agents with
two collection-valued properties, objects and agents, which represent their information state: the (non-agentive) objects and the agents they know;
two generic "event-handling" operations that are invoked by the simulator when processing perception events or message events:
- onReceive for handling in-message events (i.e., for receiving messages),
- onPerceive for handling perception events (i.e., for processing perceptions), and
two generic operations for performing actions and sending messages:
- perform for performing an action (by scheduling an action event),
- send for sending a message to one or more other agents (by scheduling a message event with one or more receivers).
Notice that actions are events and we therefore also call them action events. Sending a message corresponds to a send message action, which is also called an out-message action event.
These operations are depicted in the following diagram showing an A/OEM&S meta-model fragment:

In A/OEM&S, the behavior of an agent is based on in its event handling operations onPerceive and onReceive for reacting to perceptions and to incoming messages, as well as perform and send for performing actions and sending messages.
In a standalone (non-distributed) simulator for A/OEM&S, the most efficient way of implementing inter-agent communication is achieved by having the sender directly invoking a message reception method of the receiver (corresponding to synchronous message passing).
However, such an implementation (by direct method invocation) would bypass the fundamental event scheduling mechanism of OEM&S, which also warrants the occurrence time consistency of events. Each perception event and each action should be scheduled as an event, i.e., added to the simulator's Future Events List (FEL), such that it can be processed by the simulator on its occurrence time.
When the simulator processes a perception event as an objective (external) event from the FEL, it invokes the onPerceive event-handling method of the perceiver agent, which corresponds to a subjective (internal) perception event that is induced by the objective perception event.
In A/OEM&S, performing a send message action corresponds to scheduling a message event with a message, a sender and a receiver. When the simulator processes a message event as an objective (external) event from the FEL, it invokes the onReceive event-handling method of the receiver agent, which corresponds to a subjective (internal) message reception event that is induced by the objective message event.
There are two alternative architectures for simulating agents and their interactions with their environment and with each other:
- An interleaved architecture (based on next-event time progression) that interleaves the processing of events and the execution of agent behavior.
- A round-based architecture (based on incremental time progression) that, in a loop, transmits to each agent all perception and message events that affect it, and then waits for the resulting state changes and action events created by each agent, before it proceeds with first processing the state changes and then processing the next events. This approach guarantees that the behavior (and state changes) of an agent at each simulation step is not affected by the behavior (and state changes) of other agents at the same simulation step, but only by their past behavior (and state changes).
The interleaved architecture, allowing the immediate processing of perception events and message events by the simulator, is simpler and more efficient..
14.1. Perception and Action
Agents may perceive objects and events in their environment and, in response, take certain actions, possibly causing changes in their environment.
One can distinguish between a passive and an active form of perception. Passive perception takes place asynchronously, while an agent is busy or idle, in the form of (instantaneous) perception events, while active perception requires the agent to perform a perceptive action or activity (like scanning the neighborhood). In general, agents are exposed to perception events and may react in response to them.
In the case of physical agents, like robots, passive perception events are created by a sensor containing an event detector, such as a Proximity Infra-Red (PIR) sensor, which has its output pin going high whenever it detects an infra-red emitting object (e.g., a human or a medium to large sized animal) in its reach. Active perceptions are created by querying the measurement value of a sensor containing a quality detector, such as a DHT22 temperature and humidity sensor. The distinction between event detectors and quality detectors has been proposed in (Diaconescu and Wagner 2015).
Perception events typically lead to an update of existing beliefs or to the creation of new beliefs.
14.2. Communication
There are various forms of communication between agents. In particular, we can distinguish between verbal and non-verbal communication. We are only concerned with verbal communication, which is based on messages.
Ontological Considerations
Conceptually, a communication event is composed of two successive atomic events: an out-message event (corresponding to a send message action of the sender) and a correlated in-message event (or message reception by the receiver). This is illustrated by the following diagram:

This concept diagram expresses the following ontological stipulations:
A message is sent from a sender agent to one or more receiver agents via an out-message event.
A message from a sender agent is received by a receiver agent via an in-message event.
A communication event consists of a pair of correlated out/in message events out and in, such that the following conditions hold:
- in.message = out.message
- in.receiver is included in out.receivers
- in.sender = out.sender
- in.occurrenceTime > out.occurrenceTime
Communication events may lead to updates (and deletions) of existing beliefs or to the creation of new beliefs, especially in information exchange processes based on Tell-Ask-Reply messages.
Message Types
Each message is of a certain type defining its properties and implicit semantics. There are two kinds of message types:
- User-defined problem/domain-specific message types: the structure of such a message type is defined within a simulation model in the form of a class defining its properties; their semantics is defined in the receive methods of receiver agents in terms of how messages of such a type are processed.
- Pre-defined problem/domain-independent message types: Tell and Ask/Reply are examples of problem/domain-independent message types that may be supported by a simulator. As they refer to general speech acts, the semantics of these message types should be based on the philosophical speech act theory of Austin and Searle.

There are two prominent agent communication language standards: FIPA and KQML (Finin et al 1997), both defining domain-independent standard message types with a semantics based on speech act theory. We briefly describe the rules for processing Tell, Ask, Reply and Request messages:
- Tell
Using this message type, agents may communicate some of their beliefs to other agents, without being asked. In general, a teller may tell the truth or may lie; and in both cases the provided information may or may not be correct.
A Tell message is similar to what is called a Signal in the Unified Modeling Language (UML) where a Signal is sent asynchronously from an object to another object. The event rule for processing a Signal reception event is defined by specifying a Reception operation in the classifier of the receiver object, such that this operation has the same name as the type of the Signal (and a corresponding signature). We do not use these UML concepts (and the UML terminology) since they are too limited.
- Ask
- Using this message type, an agent may query another agent about some of its beliefs. Queries are expressed in a suitable query language, such as the RDF-based query language SPARQL. An asker expects to receive an answer via a Reply message some time later.
- Reply
- This message type is used for replying to a previously received Ask message. In general, the answers provided may or may not be correct. Therefore, askers should only update their beliefs according to the received answers when they trust the replier.
- Request
- This message type is used by an agent for requesting another agent to perform a certain action. Such a request can be either accepted or rejected.
Since a perfect information agent already has complete information about the objects it knows,
- sending a query via an Ask message only makes sense if the query may retrieve objects the sender does not yet know;
- sending an answer via a Reply message only makes sense if the answer provides information about objects the receiver does not yet know;
- receiving a statement via a Tell message only makes sense if the statement provides information about an object the receiver does not yet know.
14.3. Interleaved Agent Simulation
In interleaved agent simulation, the simulator processes a PerceptionEvent by invoking the method onPerceive of the perceiver agent. An agent performs an action, e.g., in response to a perception, with the help of its perform method, which schedules a corresponding ActionEvent that is then processed by the simulator.
Likewise, message-based communication is implemented by having the sender agent invoking its send method, which schedules a MessageEvent that is then processed by the simulator by invoking the onReceive method of the receiver agent. In this way, a MessageEvent is inserted into the simulation log and it is guaranteed that, as required above, the time when a message is received is later than the time it has been sent (in.occurrenceTime > out.occurrenceTime).
Perception and Action
For supporting perception events and actions, the OEM&S concept Event is extended in the following way:

This means that
- The pre-defined (abstract) object type Agent has two abstract methods for perception and action:
- onPerceive to be invoked with a perception argument, which is a PerceptionEvent,
- perform to be invoked with an action argument, which is an Action.
- There are two pre-defined (abstract) event types: PerceptionEvent and Action.
- A PerceptionEvent has a perceiver reference and may have additional attribute values.
- When a PerceptionEvent is processed by the simulator, it invokes the onPerceive method of the perceiver agent and passes the perception (event). This implies that the code for realizing the effects of a perception event is included in the agent class (in its definition of the onPerceive method).
- An Action event has a performer reference and may have additional attribute values.
- When an agent performs an action by invoking the perform method, an Action event is scheduled, which is then processed by the simulator by invoking the onEvent method defined in the action event class. This implies that the code for realizing the effects of an action is included in the action event class (in its definition of the action event handler onEvent).
Message-Based Communication
The following diagram shows the new A/OEM&S elements added to the OEM&S meta-model:

This means that
- The pre-defined (abstract) class Agent has the abstract method onReceive to be invoked with a message and a sender reference.
- There is a pre-defined event type MessageEvent.
- A MessageEvent has a message attribute value, which is a string or a composite value.
- When a MessageEvent occurs, the simulator invokes the onReceive method of the receiver agent and passes the message attribute value. This implies that the code for realizing the effects of an in-message event is included in the agent class (in its definition of the onReceive method).
In a distributed simulator for A/OEM&S, where all agents of a simulation scenario run as different processes (on different computers) without a shared simulator state, and, consequently, message passing would be asynchronous, it would be natural to implement both out-message events and in-message events, as described above.
Agent-Based Simulation with OESjs
Typically, a sender agent sends a message (or schedules a MessageEvent) within its onPerceive or onReceive methods, that is, in response to a perception or to a message reception. In OESjs-Core4, this could be programmed in the following way:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | class Doctor extends aGENT {
constructor({ id, name, status}) {
super( id, name);
this.status = status;
}
onReceive( msg, sender) {
switch (msg.type) {
case "ASK":
const answer = this.processQuery( msg.query),
reply = new rEPLY( answer),
receiver = sender;
this.send( reply, receiver));
break;
case "REPLY":
...
}
}
} |
Often, a PerceptionEvent is scheduled as a consequence of an action event with the meaning that the action is perceived by another agent. A PerceptionEvent is processed by the simulator by invoking the onPerceive method of the perceiver agent while passing the perception attribute value.
An Action is typically performed by an agent within its onPerceive or onReceive methods in response to a perception or to a message reception. In OESjs, this could be programmed in the following way:
1 2 3 4 5 6 7 8 9 10 11 12 13 | class Doctor extends aGENT {
constructor({ id, name, status}) {
super( id, name);
this.status = status;
}
onPerceive( perceptionEvt) {
switch (perceptionEvt.constructor.name) {
case "CovidSymptom":
this.perform( new aCTION("performPCR"));
break;
}
}
} |
Chapter 15. Basic Agents with Imperfect Information
Basic agents with imperfect information have incomplete information about the objects (and agents) they know, and they may have incorrect information.
Chapter 16. Contracts
Contracts regulate the behavior of the contract parties in the scope of a business relationship. Since nation states impose contract laws upon their legal entities, the clauses of a contract are legally binding, that is, they can be legally enforced if the contract has been violated by a party.
Based on the work of the philosophers of law Hohfeld and Alexy, as summarized in the UFO-L article, we model contract clauses as defining
- either legal entitlements: rights, permissions, powers, and immunities;
- or legal burdens: duties, no-rights, subjections, and disabilities.
Per Leif Wenar in Stanford Encyclopedia of Philosophy: “Rights are: (1) entitlements [not] to perform certain actions, or [not] to be in certain states; and/or (2) entitlements that others [not] perform certain actions or [not] be in certain states”.
Legal entitlements and legal burdens are complementary in the sense that
Another inspiring work is Symboleo (see their SoSyM 2022 article "Specification and Analysis of Legal Contracts with Symboleo").
Chapter 17. Cognitive Agents
T.B.D.
Bibliography
- Aalst, Wil M. P. van der. 2021. "Concurrency and Objects Matter! Disentangling the Fabric of Real Operational Processes to Create Digital Twins". In A. Cerone and P. C. ̈Olveczky (Eds.): Proceedings of International Colloquium on Theoretical Aspects of Computing (ICTAC 2021), LNCS 12819, pp. 3–17.
- Allen, G.N., and S.T. March. 2003. Modeling temporal dynamics for business systems. Journal of Database Management, 14, 21–36.
- Almeida, J.P.A., R. Falbo and G. Guizzardi. 2019. Events as Entities in Ontology-Driven Conceptual Modeling, in Proceedings of 38th International Conference on Conceptual Modeling, ER 2019, Salvador, Brazil, November 4–7, 2019.
- Diaconescu, M. and G. Wagner. 2015. Modeling and Simulation of Web-of-Things Systems Part 1: Sensor Nodes. In L. Yilmaz, W. K. V. Chan, I. Moon, T. M. K. Roeder, C. Macal and M. D. Rossetti (Eds.), Proceedings of the 2015 Winter Simulation Conference. pp. 3061–3072. Piscataway, New Jersey: Institute of Electrical and Electronics Engineers. http://www.informs-sim.org/wsc15papers/300.pdf
- Casati, R., and A. Varzi, Events, in: E.N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy, 2015.
- Chen, P. 1976. The entity-relationship model – toward a unified view of data. ACM Transactions on Database Systems, 1(1):9–36.
- Fine, K. 2022. Acts and embodiment, Metaphysics, 5:1, 14–28.
- Finin T., Y. Labrou and J. Mayfield. 1997. KQML as an agent communication language. In J. Bradshaw (Ed.), Software Agents, MIT Press, Cambridge.
- Gordon, G. 1961. A general purpose systems simulation program. In AFIPS '61: Proceedings of the Eastern Joint Computer Conference, 87–104, New York: Association for Computing Machinery.
- Griffo, C., J.P.A. Almeida, G. Guizzardi, and J.C. Nardi. 2021. Service contract modeling in Enterprise Architecture: An ontology-based approach, Information Systems 101.
- Guarino, N., and G. Guizzardi. 2024. Processes as variable embodiments. Synthese vol. 203, article no. 104. https://doi.org/10.1007/s11229-024-04505-2
- Guarino, N., and C. Welty. 2009. An Overview of OntoClean. In Handbook on Ontologies. https://doi.org/10.1007/978-3-540-92673-3_9.
- Guizzardi, G. 2005. Ontological Foundations for Structural Conceptual Models. PhD thesis, CTIT PhD Thesis Series, No. 05-74 Telematica Instituut Fundamental Research Series, No. 015 (TI/FRS/015).
- Guizzardi, G., A. Botti Benevides, C. M. Fonseca, D. Porello, J. P. A. Almeida, and T. P. Sales. 2022. UFO: Unified Foundational Ontology, Applied Ontology 17, 1–44.
- Loch C.H. 1998. Operations Management and Reengineering, European Management Journal 16, pp. 306–317.
- March, S., and G. Allen. 2009. Conceptual Modeling of Events for Active Information Systems. In Sugumaran, V. (Ed.). Distributed Artificial Intelligence, Agent Technology, and Collaborative Applications. IGI Global. https://doi.org/10.4018/978-1-60566-144-5
- Markowitz, H., B. Hausner, and H. Karr. 1962. SIMSCRIPT: A Simulation Programming Language. Englewood Cliffs, N. J.: Prentice Hall. Available from https://www.rand.org/content/dam/rand/pubs/research_memoranda/2009/RM3310.pdf
- McCarthy, W.E. 1979. An Entity-Relationship View of Accounting Models. The Accounting Review, Vol. LIV, No. 4.
Pegden, C.D. and D.A. Davis. 1992. “Arena: a SIMAN/Cinema-Based Hierarchical Modeling System”. In Proceedings of the 1992 Winter Simulation Conference, edited by J.J. Swain, D. Goldsman, R.C. Crain, and J.R. Wilson, 390–399. Piscataway, New Jersey: Institute of Electrical and Electronics Engineers, Inc.
- Pegden, C.D. 2010. “Advanced Tutorial: Overview of Simulation World Views”. In Proceedings of the 2010 Winter Simulation Conference, edited by B. Johansson, S. Jain, J. Montoya-Torres, J. Hugan, and E. Yücesan, 643−651. Piscataway, New Jersey: Institute of Electrical and Electronics Engineers, Inc. Available from http://www.informs-sim.org/wsc10papers/019.pdf
- Petri, C. A. 1962. Kommunikation mit Automaten. Ph. D. thesis, Institut für Instrumentelle Mathematik, Bonn. English Translation, 1966: Communication with Automata, Technical Report RADC-TR-65-377, Rome Air Development Center, Air Force Systems Command, Griffiss Air Force Base, New York.
- Ross, R.G. 2023. Rules: Shaping Behavior and Knowledge. Business Rule Solutions, LLC.
- Russell, N., A. H. ter Hofstede, D. Edmond, and W. M. van der Aalst. 2004. Workflow Resource Patterns. http://www. workflowpatterns.com/patterns/resource/, accessed 2022-04-15.
- Schruben, L.W. 1983. Simulation Modeling with Event Graphs. Communications of the ACM 26, pp. 957–963. https://dl.acm.org/citation.cfm?id=358460
- Tauzovich, B. 1991. Toward Temporal extensions of the Entity-Relationship Model. Proceedings of the 10th International Conference on Entity Relationship Approach, San Mateo, California: E-R Institute, pp. 136-179.
- Standridge, C.R. 2013. Beyond Lean: Simulation in Practice, Second Edition, Open Access book, available from https://scholarworks.gvsu.edu/cgi/viewcontent.cgi?article=1006&context=books.
- Vincent, P., K. Iijima, A. Leow, M. West, and O. Matvitskyy. 2022. Magic Quadrant for Enterprise Low-Code Application Platforms. Gartner Report G00759450.
- Wagner, G. 2017. An Abstract State Machine Semantics for Discrete Event Simulation. In Proceedings of the 2017 Winter Simulation Conference. Piscataway, NJ: Institute of Electrical and Electronics Engineers. Available from https://www.informs-sim.org/wsc17papers/includes/files/056.pdf.
- Wagner, G. 2018. Information and Process Modeling for Simulation – Part I: Objects and Events. Journal of Simulation Engineering, vol. 1, 2018. https://articles.jsime.org/1/1.
- Wagner, G. 2022. Object Event Modeling for DES and IS Engineering. Proceedings of the ER Forum 2022. In: Link, S., I. Reinhartz-Berger, J. Zdravkovic, D. Bork and S. Srinivasa (Eds.). volume 3211. CEUR Workshop Proceedings.
- Zeigler, B.P. 1976. Theory of Modeling and Simulation. Wiley, New York.